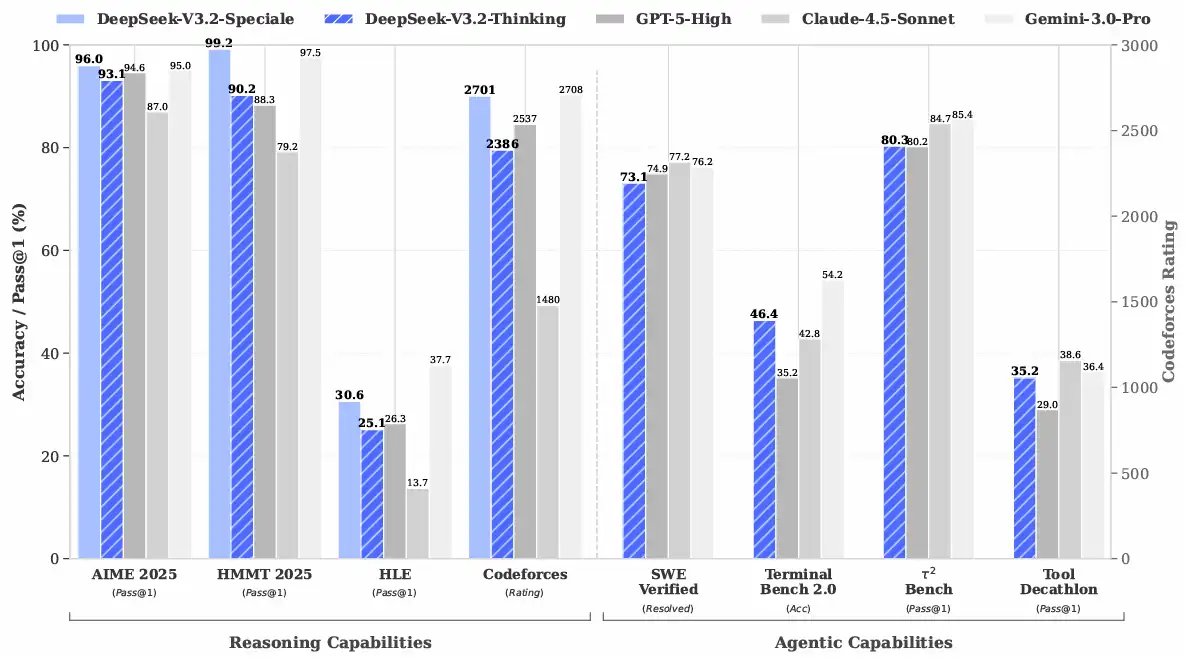
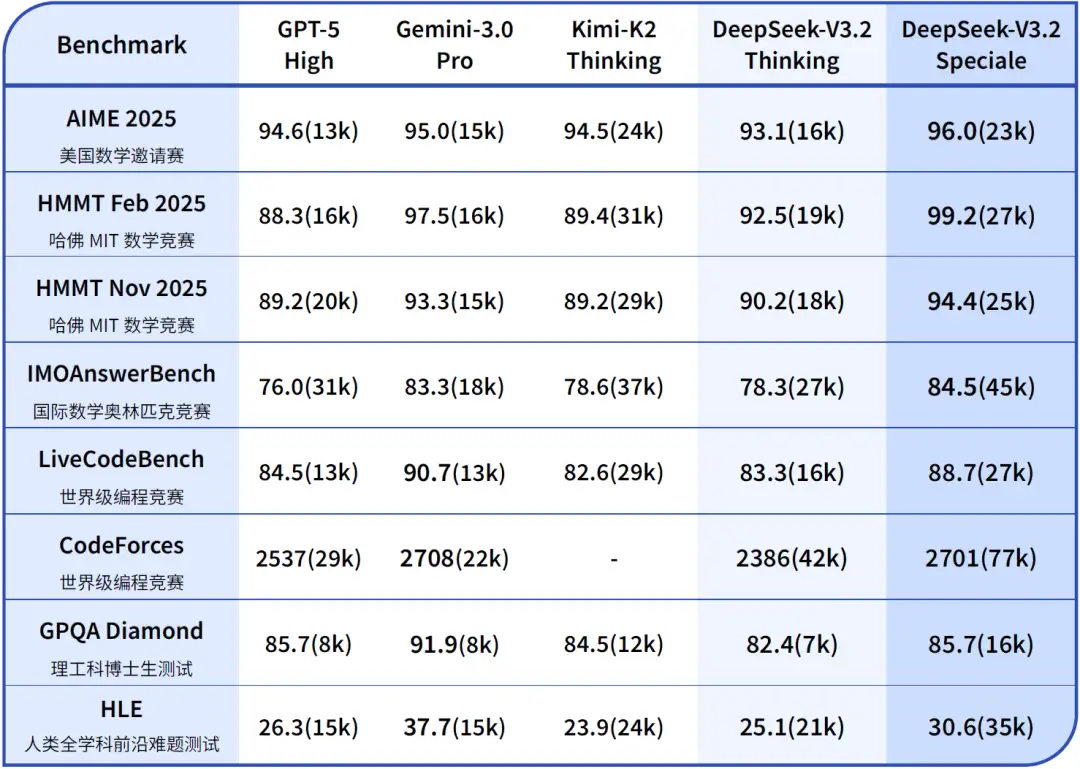
复杂问题推理能力大幅提升,DeepSeekAI发布DeepSeek V3.2正式版本以及一个评测结果可以媲美Gemini 3.0 Pro的将开源模型推到极限性能的DeepSeek-V3.2-Speciale模型
几个小时前,DeepSeek 突然发布了两款全新的推理模型:DeepSeek V3.2 正式版与DeepSeek V3.2-Speciale。前者已经全面替换官方网页、App 与 API 成为新的默认模型;后者则以“临时研究 API”的方式开放,被定位为极限推理版本。

这次发布吸引了社区立刻刷屏,不仅因为又多了两个新型号,更因为它们分别代表了开源模型两个截然不同的方向:一个负责日常生产,一个负责探索推理边界。
两个月前,DeepSeek 把 DeepSeek V3.2-Exp 推到线上,明确标注“实验版”。验证他们提出的DSA的效果。
DSA全称为DeepSeek Sparse Attention:
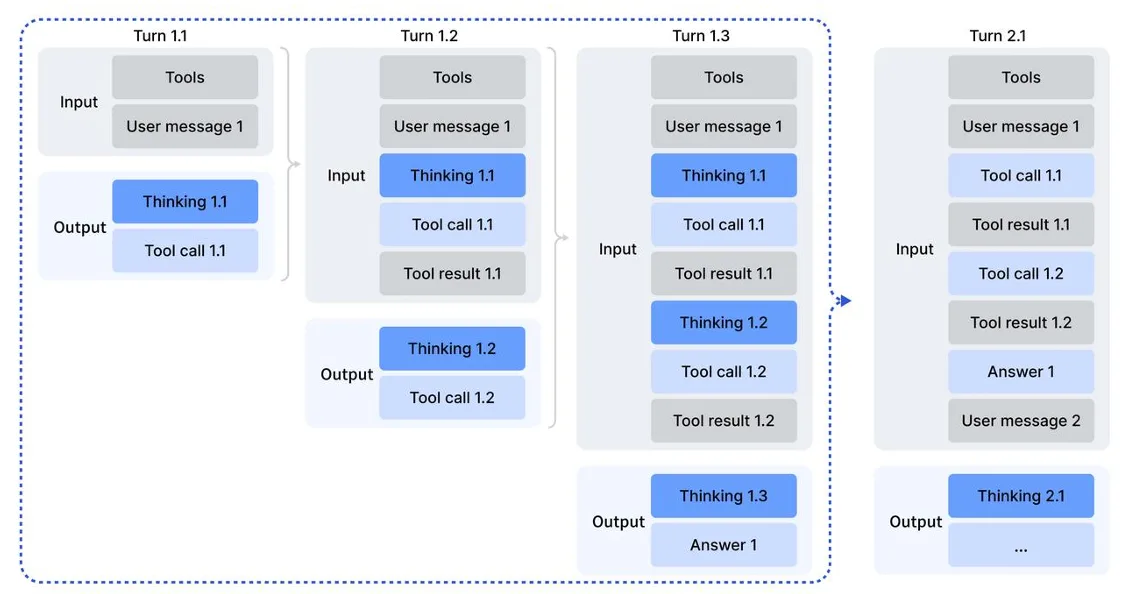
DSA 让模型不必再对长达数十万 Token 的上下文“全部计算注意力”,而是先预测哪些内容重要,再对这些内容做精细计算。
换成更直观的比喻:传统注意力像学生复习时把所有资料都从头读到尾,累、慢、效率低。DSA 像有个“索引助手”,先快速浏览所有资料,再告诉你:“最关键的就这 5%”。模型随后只对这些内容精算注意力。因此 DSA 的直接效果是:
- 长上下文成本下降(越长越明显)
- 推理速度提升
- 稳定性更强,思考链不容易被上下文噪声干扰
这套机制在 DeepSeek V3.2-Exp 上首次大规模实战,官方希望确认:在不大幅动模型主体的前提下,把 DSA 这套稀疏注意力接到原有框架里,看看在真实用户的长对话、复杂推理和 Agent 使用中会不会翻车。结果比很多人预期得更乐观——大量社区对比测试显示,在多数场景中,DeepSeek V3.2-Exp 并不逊于DeepSeek V3.1-Terminus,没有出现明显的“减分场景”,却带来了更好的长上下文效率。这等于给 DSA 交上了一份“生产可用”的答卷。
今天上线的 DeepSeek V3.2 正式版,就是在这套架构验证之上,完成的一次「真正意义上的完整模型」。同时亮相的 ,则把推理能力进一步推到竞赛级金牌的高度。一个主打“日用 + Agent”,一个主打“极限推理 + 思考深度”,共同勾勒出 DeepSeek 在新一代推理模型上的完整布局。