强烈推荐!清华大学100亿参数规模的免费商用授权大模型:CPM-Bee 10B
3,119 阅读
最近几个月,国产大语言模型进步十分迅速。不过,大多数企业发布的大模型均为商业产品,少数开源的LLM则有较高的商业授权费用或者商用限制。对于希望使用LLM能力的中小企业以及个人来说都不是很合适。本次给大家介绍的是目前国产开源领域里面一个十分优秀且具有潜力的大语言模型CPM-Bee 10B。该模型来自清华大学NLP实验室,参数规模100亿,最重要的是对个人和企业用户均提供免费商用授权,十分友好!
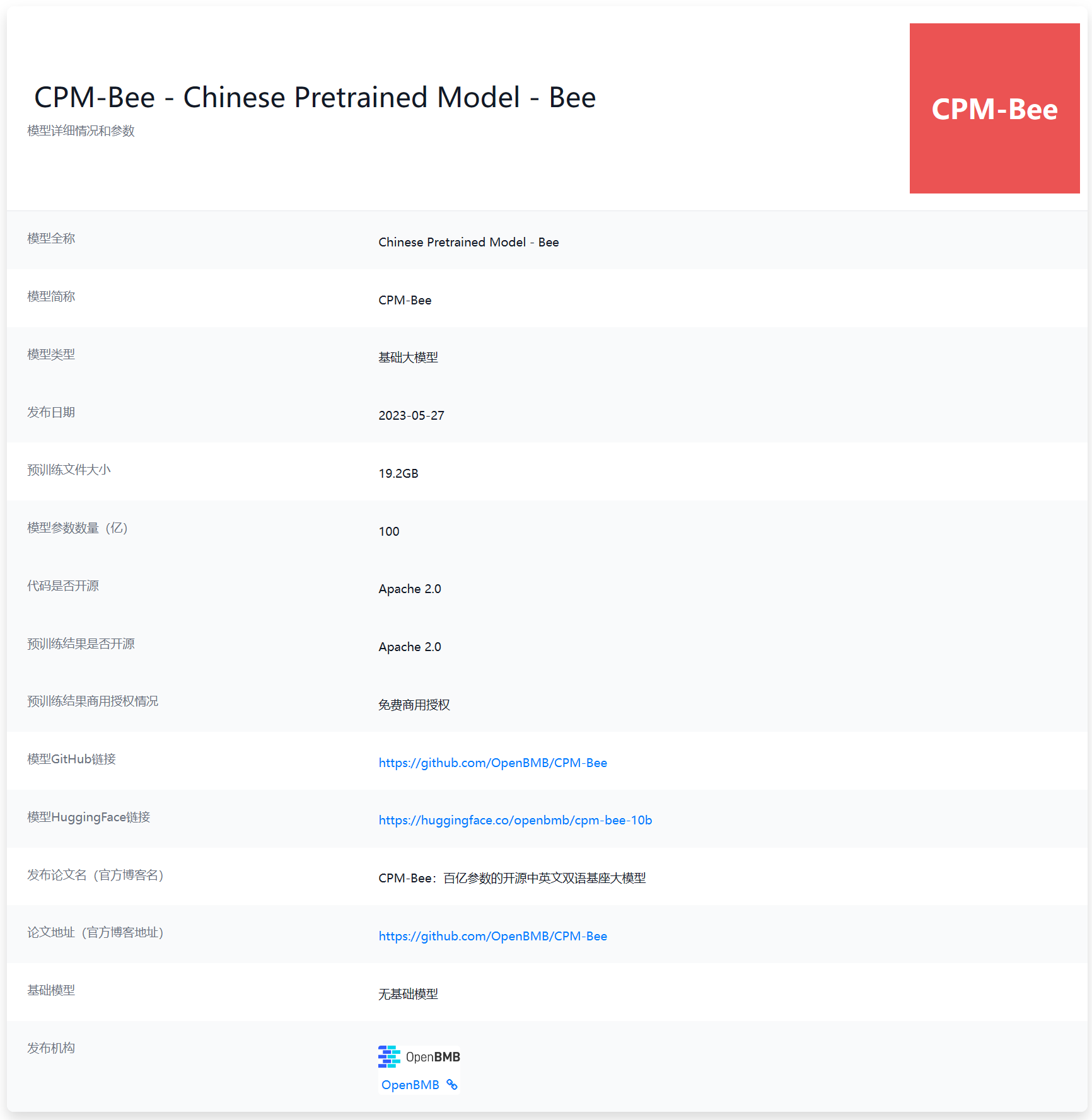
CPM-Bee 10B简介
一个月之前,清华大学NLP小组发布了一个100亿参数规模的基础大语言模型CPM-Bee 10B,该模型基于超过1万亿tokens的数据集上训练,中文支持十分友好,是国产领域非常优秀的模型。具体来说,该模型有如下特点:
- 训练质量较高:CPM-Bee 10B在超过1万亿tokens的数据集上训练,训练数据中包含200GB高质量中文数据集,且模型参数达到100亿,在国产开源领域目前应该是最优秀的一类(ChatGLM-6B和Baichuan 7B开源模型参数规模只有60-70亿,复旦大学的MOSS开源模型参数规模虽然有160亿,但是训练数据只有7000多tokens)。
- 社区生态良好:开源大模型一个很重要的方面是社区的支持和生态的丰富程度。不同的人对LLM的使用需求差异很大,因此对模型微调和改造是开源LLM是否吸引人的重要因素。CPM-Bee 10B在GitHub上开源并提供了模型微调、模型联网等内容和工具,并且背后有一个OpenBMB社区提供官方支持,对于使用者来说非常友好。
- 模型易用性高:CPM-Bee已经整合到HuggingFace的著名开源库transformers中,可以直接按照transformer官方使用方法调用,与主流生态兼容性高。而在使用方面,官方还提供了微调脚本,只需要准备好数据即可直接运行微调脚本获得在我们自己数据集上微调后的大模型,十分简单方便。