可以在手机端运行的大模型标杆:微软发布第三代Phi-3系列模型,评测结果超过同等参数规模水平,包含三个版本,最小38亿,最高140亿参数
1,203 阅读
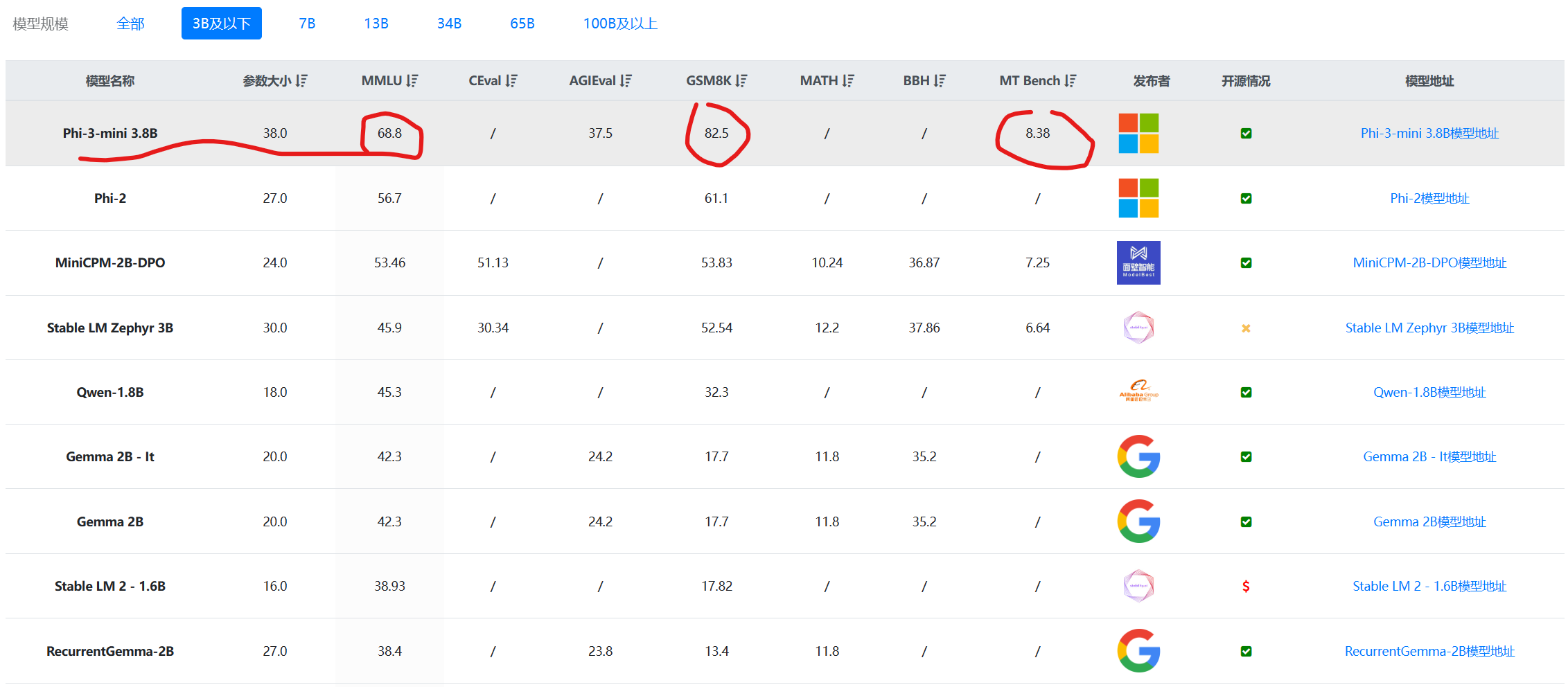
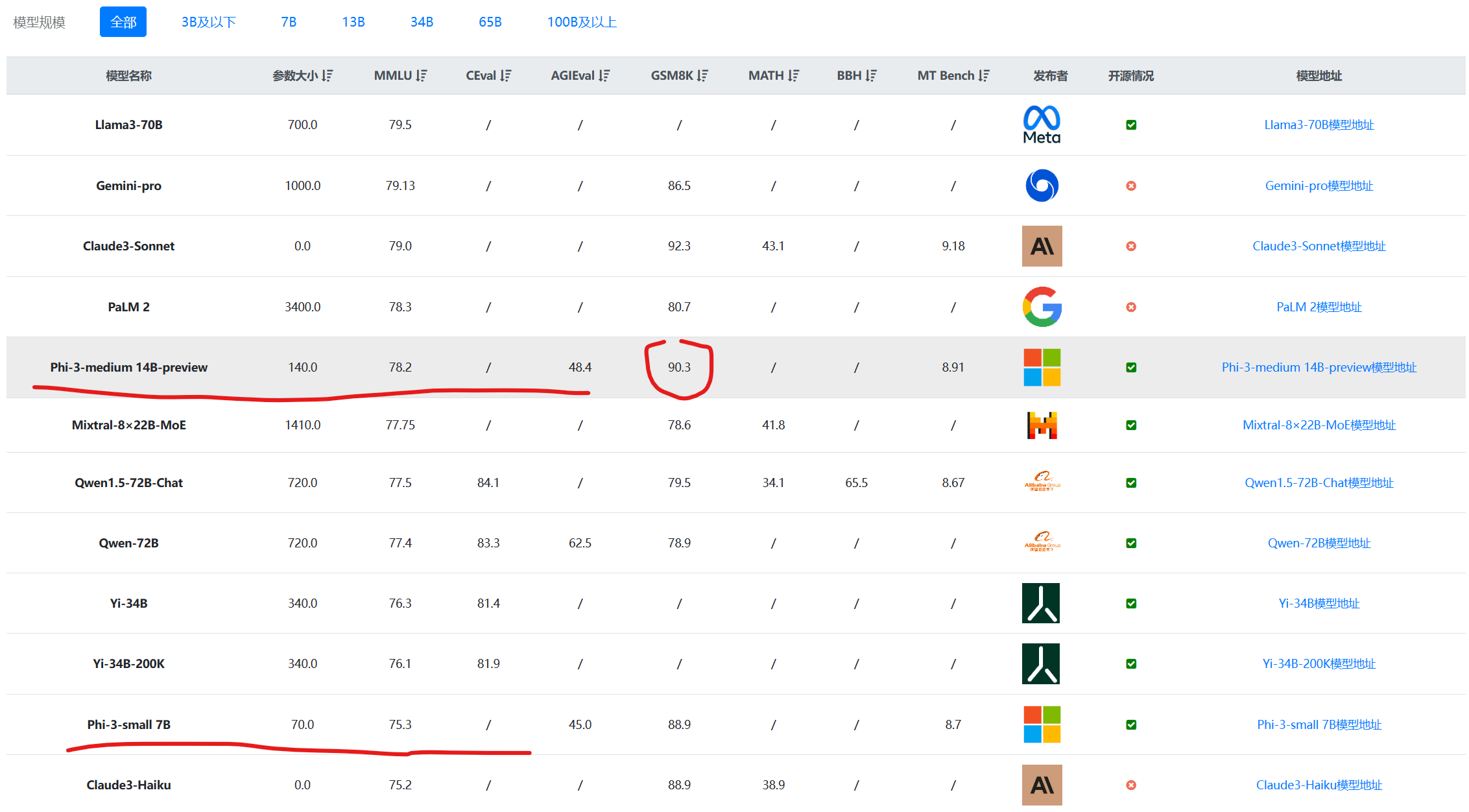
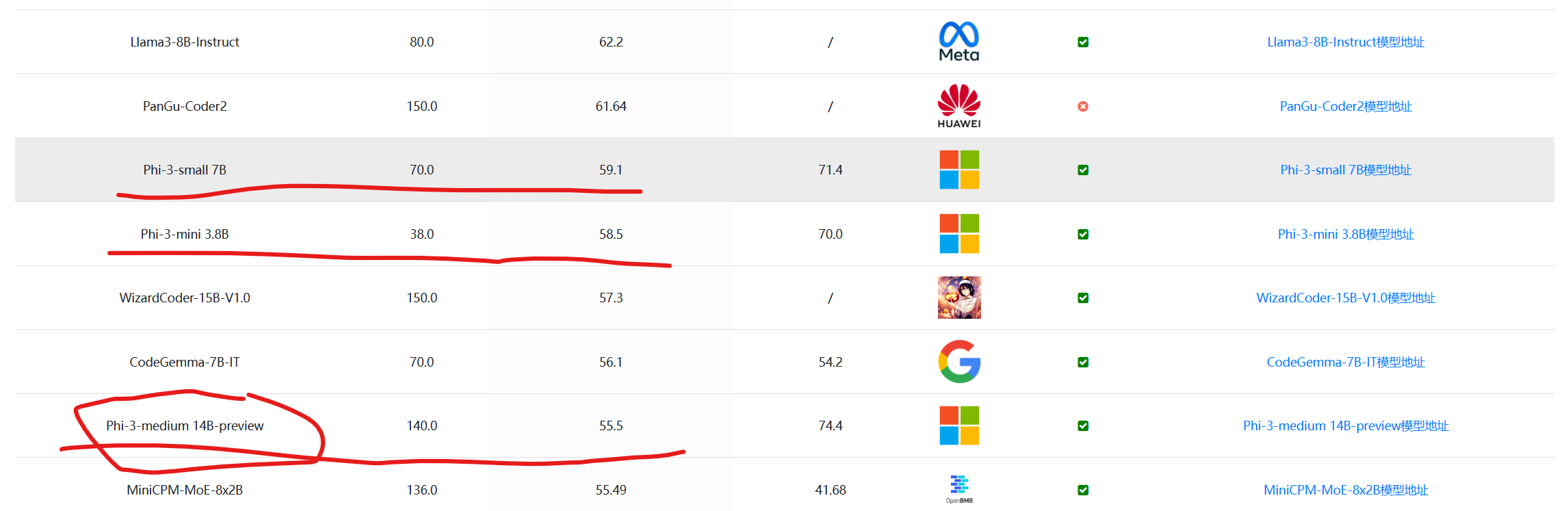
Phi系列大语言模型是微软开源一个小规模参数的语言模型。第一代和第二代的Phi模型参数规模都不超过30亿,但是在多个评测结果上都取得了非常亮眼的成绩。今天,微软发布了第三代Phi系列大模型,最高参数规模也到了140亿,其中最小的模型参数38亿,评测结果接近GPT-3.5的水平。

Phi系列模型简介
大语言模型的一个重要应用方向就是在手机端运行。为此,30亿参数规模几乎是上限(超过这个规模的模型,需要通过量化等手段牺牲模型性能)。在这其中,微软的Phi系列模型是最具有竞争力的。
Phi系列模型的目的是希望在小规模参数的模型上获得传统大模型的能力。在2023年6月份,微软开源了第一代Phi模型,这个模型参数规模仅有13亿,这是一个纯粹的编程大模型,但是效果不错,三个月后,微软发布Phi-1.5模型,在Phi-1代码补全的基础上增加了模型推理能力和语言理解的能力,参数量不变。随后,2023年年底微软开源了Phi-2模型,这个模型的参数增长到27亿,但是MMLU评测结果超过了LLaMA2 13B,让大家十分惊叹。
四个月后的今天,微软发布了第三代Phi模型,这一代的模型最小参数38亿,最大规模拓展到了140亿,包含3个版本,分别是Phi-mini-3.8B、Phi-small-7B和Phi-medium-14B。参数规模增长的同时,能力也大幅提高。
第三代Phi-3模型简介
第三代的Phi模型是微软继续探索小规模参数语言模型的成果。尽管Phi-3包含了70亿和140亿两个较大规模版本的模型。但是最小的38亿参数模型依然可以在手机端运行。