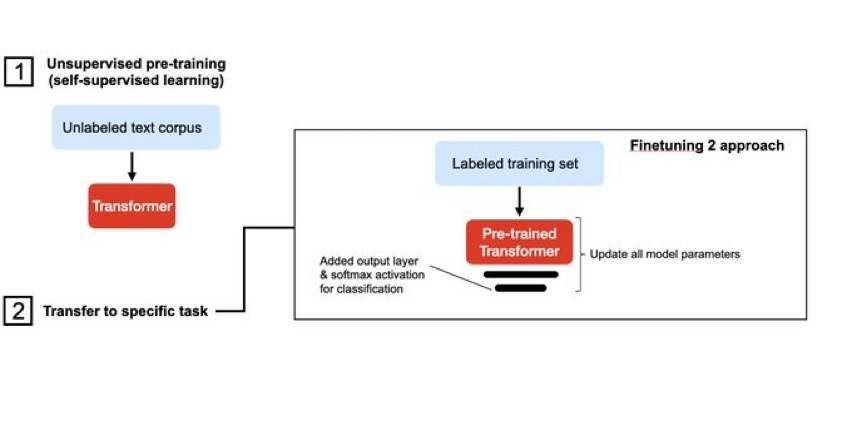
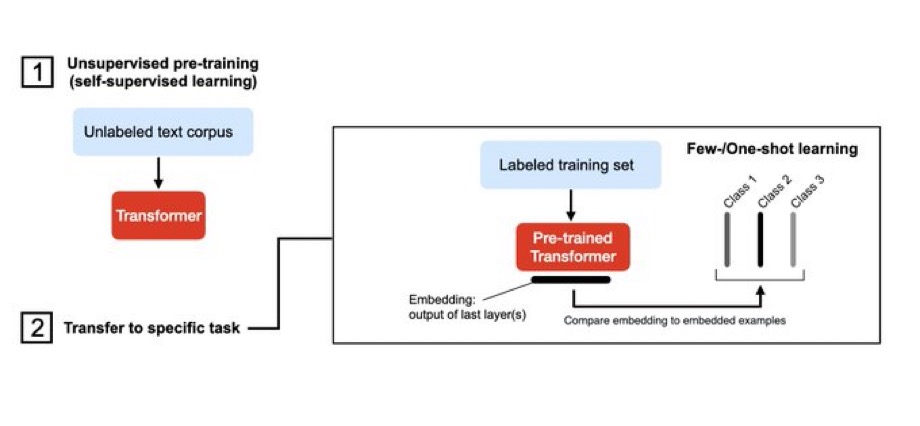
6张示意图解释6种语言模型(Language Transformer)使用方式
1,889 阅读
近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。
一、从头开始训练(Train from scratch)
从头训练一个transformer是最基本的使用方法,只是一般来说transformer模型需要大量的数据,实际场景很难获取这么多有标注的数据做训练。所以当前的transformer模型的训练都是使用unlabeleds数据做预训练,这与有监督学习的模型训练方式差别很大。
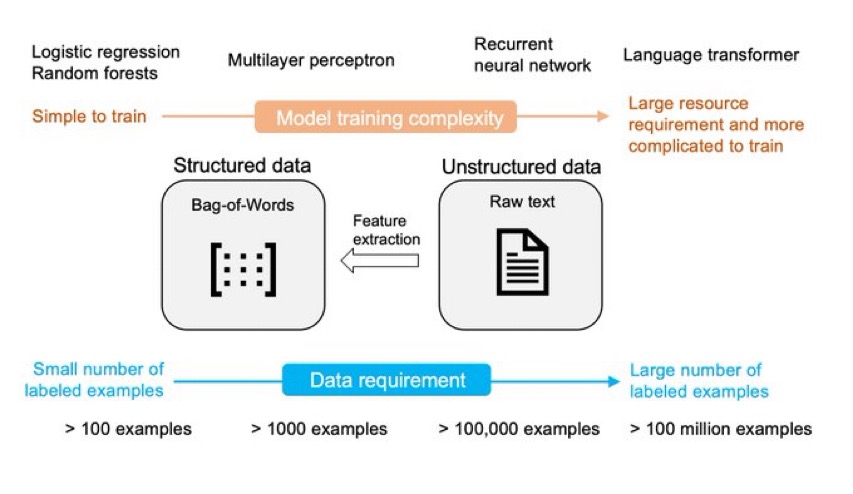
二、基于特征的方式:在embeddings的基础上训练新模型(Train new model on embeddings)
使用一个现成的transformer模型,将最后一层删除,然后使用推理的方式运行大语言模型,在embeddings上训练新的分类器。