大语言模型的技术总结系列一:RNN与Transformer架构的区别以及为什么Transformer更好
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。本文是大语言模型技术系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
需要注意的是,如果想彻底弄清楚RNN和Transformer的底层技术原理需要大家看懂它们的公式,而本文主要的目的是尽量在不涉及公式的前提下说清楚二者的区别。对于RNN本身的介绍以及Transformer结构的介绍不多,核心是说清楚二者的区别。因此,需要如果大家对RNN和Transformer有一点基本的了解,应该看起来很容易。
语言模型简介
语言模型是一种基于统计学和机器学习方法的自然语言处理技术,它用于评估和预测一个给定序列的概率分布,通常是单词序列或字符序列。语言模型的主要应用是文本生成、机器翻译、语音识别等任务。
最初的语言模型是基于n-gram方法的,其中n代表前n个单词或字符的组合。然而,n-gram方法的局限性在于它仅考虑了有限数量的历史单词或字符,无法捕捉长期依赖性。近年来,深度学习方法已成为语言模型的主流技术。特别是循环神经网络(RNN)和Transformer等模型已成为语言模型的热门选择,它们可以处理任意长度的序列,并且能够捕捉长期依赖性。
近些年,神经网络架构的语言模型参数规模已经达到几千亿,为了表示与传统语言模型的区别,大家习惯称之为大语言模型。大语言模型与某些传统语言模型的架构可能差不多,但是参数规模的变化也让大语言模型有很多小规模模型无法拥有的特点,可以说,参数规模几乎是目前语言模型强大能力的必要条件。
RNN模型简介
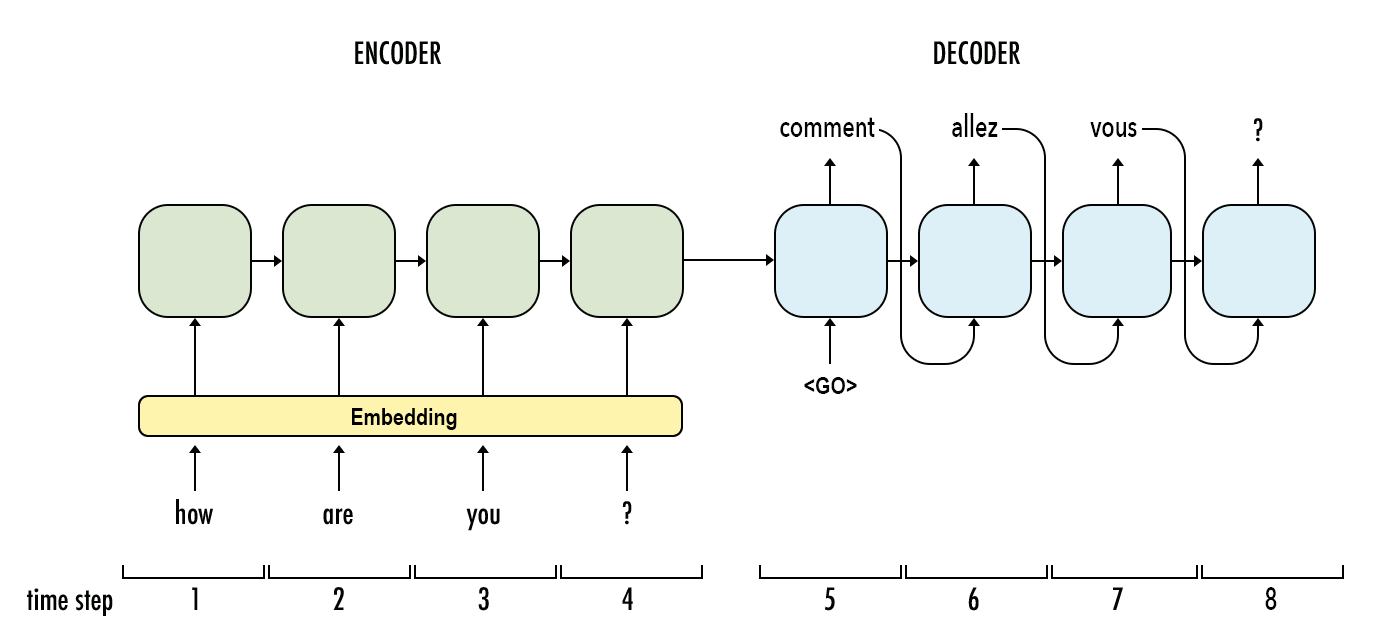
RNN(循环神经网络)和Transformer是两种用于处理序列数据的常见神经网络架构,它们的主要区别在于模型的架构和处理序列数据的方式。
RNN是一种经典的序列模型,它通过循环的方式将序列中的信息逐个输入到网络中,并在网络内部使用循环结构来捕捉序列中的时间依赖关系。RNN的输出通常是与序列长度相关的固定大小的向量,可以用于下游任务,如文本分类、命名实体识别等。然而,由于长期依赖性问题,RNN在处理长序列时可能存在梯度消失或爆炸的问题。下图是一个典型的RNN架构的模型: