清华大学ChatGLM团队发布AI Agent能力评测工具AgentBench:GPT-4一骑绝尘,chatglm2表现优秀,baichuan-7b排名倒数!
4,487 阅读
所谓AI Agent就是一个以LLM为核心控制器的一个代理系统。业界开源的项目如AutoGPT、GPT-Engineer和BabyAGI等,都是这样的系统。然而,并不是所有的AI Agent都有很好的表现,其核心还是取决于LLM的水平。尽管LLM已经在许多NLP任务上取得进步,但它们作为代理完成实际任务的能力缺乏系统的评估。清华大学KEG与数据挖掘小组(就是发布ChatGLM模型)发布了一个最新大模型AI Agent能力评测数据集,对当前大模型作为AI Agent的能力做了综合测评,结果十分有趣。
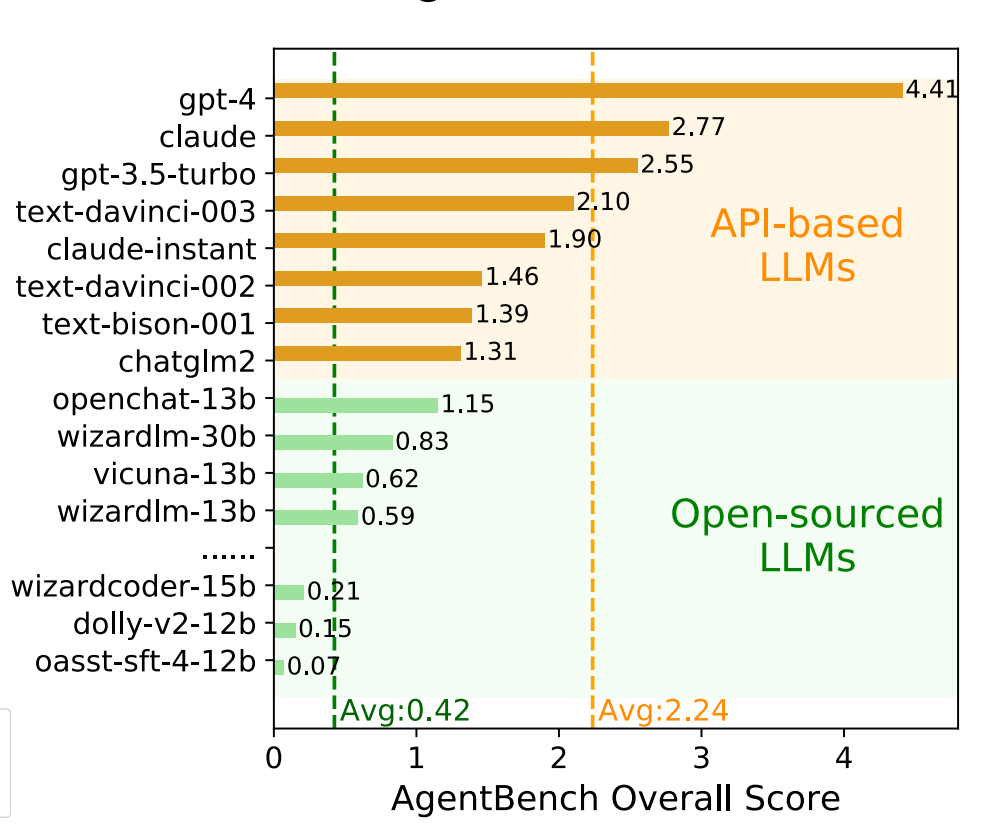
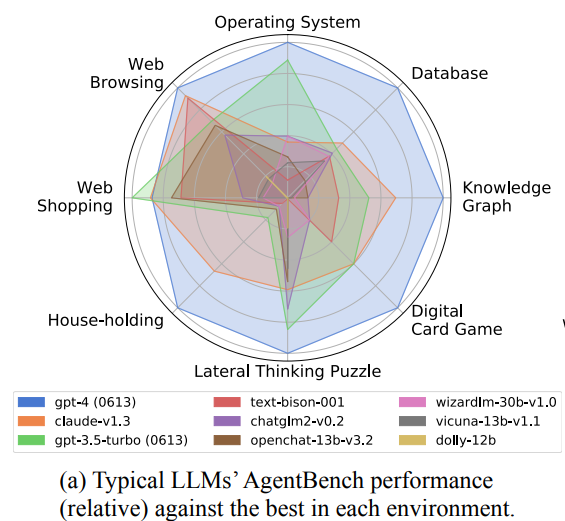
这个AgentBench是评测LLM作为Agent的能力,通过评测LLM在细分任务的得分来确定LLM作为Agent的水平,主要结论就是商业模型表现远超开源模型,更加适合作为Agent来使用,而GPT-4更是一骑绝尘,成为唯一一个超越4分的模型,其它模型连3分都没有!
AI Agent简介
所谓AI Agent就是一个以LLM为核心控制器的一个代理系统。可以通过识别用户的意图,使用可用的工具,完成设定的目标。

也就是说,AI Agent本质是一个控制LLM来解决问题的代理系统。LLM的核心能力是意图理解与文本生成,如果能让LLM学会使用工具,那么LLM本身的能力也将大大拓展。AI Agent系统就是这样一种解决方案。
AI Agent被很多人认为是LLM能力升级的一个重要方式,就连OpenAI的研究人员也认为AI Agent是LLM转为通用问题解决方案的途径之一(参考:大模型驱动的自动代理(AI Agent):将语言模型的能力变成通用能力的一种方式——来自OpenAI安全团队负责人的解释与观点)。