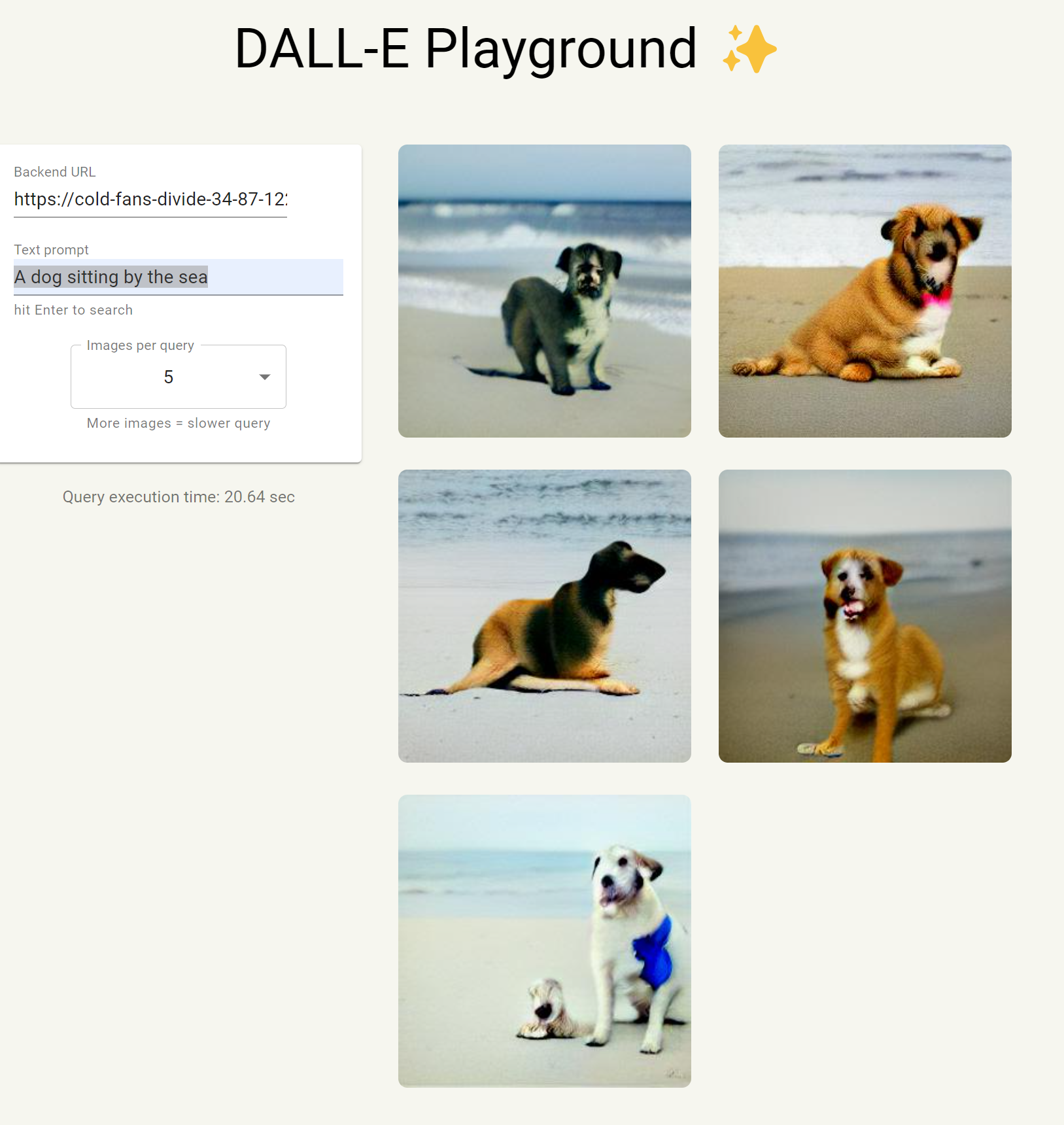
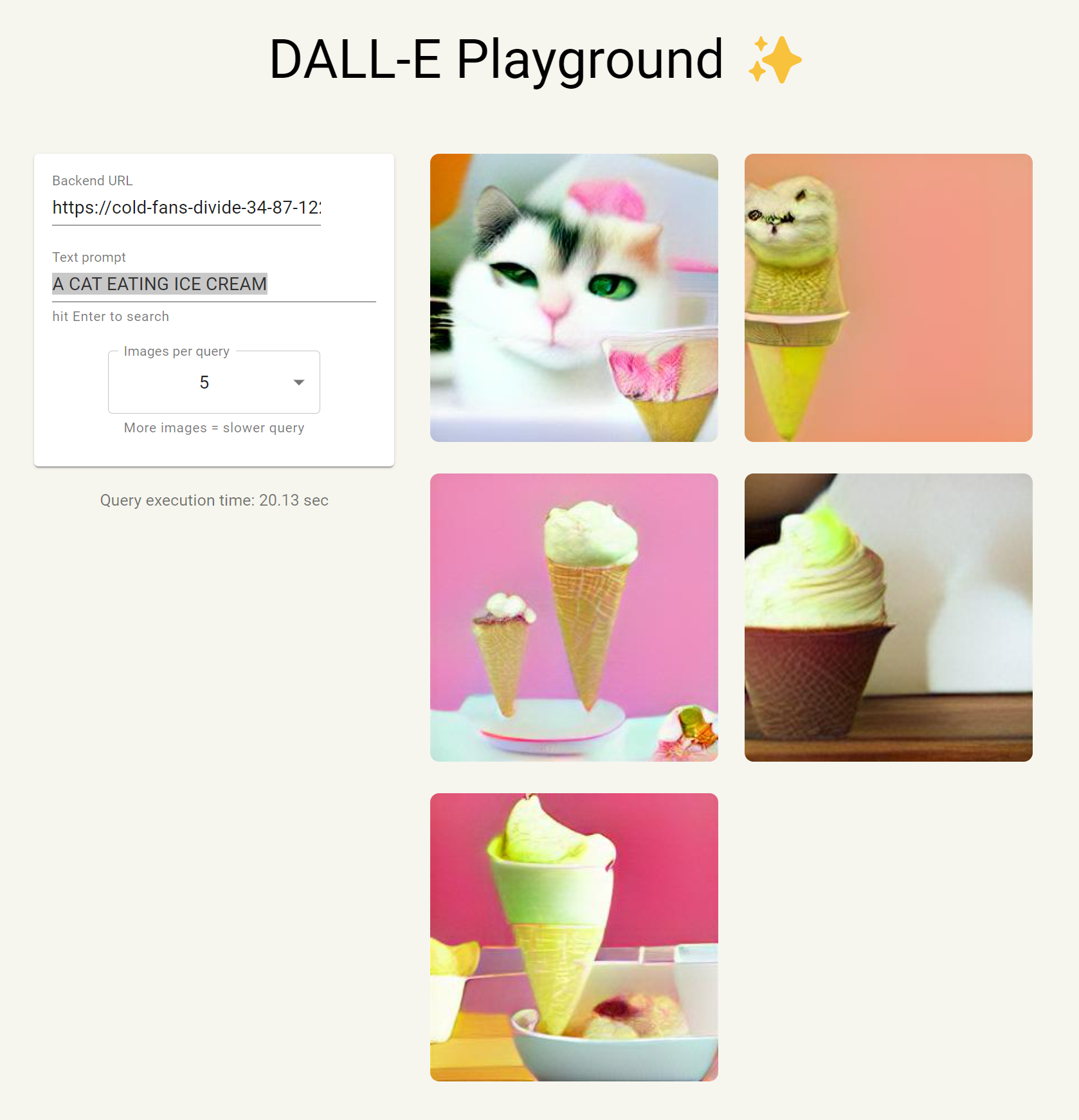
简单几步教你如何在搭建并使用DALL·E开源版本来基于文字生成图片
基于文本生成图像是NLP和CV领域这几年非常火热的领域,而OpenAI在2021年发布了DALL·E2和谷歌的大概是第一个大规模预训练模型里专门用来生成图片的模型(这也是一个120亿参数版本的GPT-3,官方说专门用来做text-to-image的)。而最近这段时间,DALL·E2和谷歌的Imagen的出现,展示了更高质量的图片生成模型(OpenAI第二代DALL·E发布,可以使用自然语言创造和编辑图片的模型)。
不过,两家都没有将这些模型公开,OpenAI的意思就是我这玩意太厉害,随便放出来可能会被你们做坏事,而谷歌训练这个应该就是为了云服务挣钱,所以都没有公开可用的版本供大家玩耍。虽然业界有基于论文的实现,但是训练模型需要耗费大量的资源,没有开放的预训练结果,我们普通个人也很难玩起来。但是,大神Sahar提供了一个免费使用开源实现的text-to-image预训练模型的方式。
首先,业界已经有Boris Dayma童鞋开发了开源实现和训练的复刻DALL·E模型的代码。目前已经公开可用的包括DALL·E mini。这个版本已经可以在hugging face上使用了:https://huggingface.co/spaces/dalle-mini/dalle-mini
而这位童鞋的更高级的DALL·E Mega正在训练中,还没完全训练完。不过,这些训练也是耗费钱的,所以即便公开可用,咱们自己机器也很难搞起来。
而Sahar老哥在GitHub上开源的代码可以帮助我们使用已经训练好的DALL·E mini等来搭建自己的text-to-image,一周时间已经有了1.1k的star了。
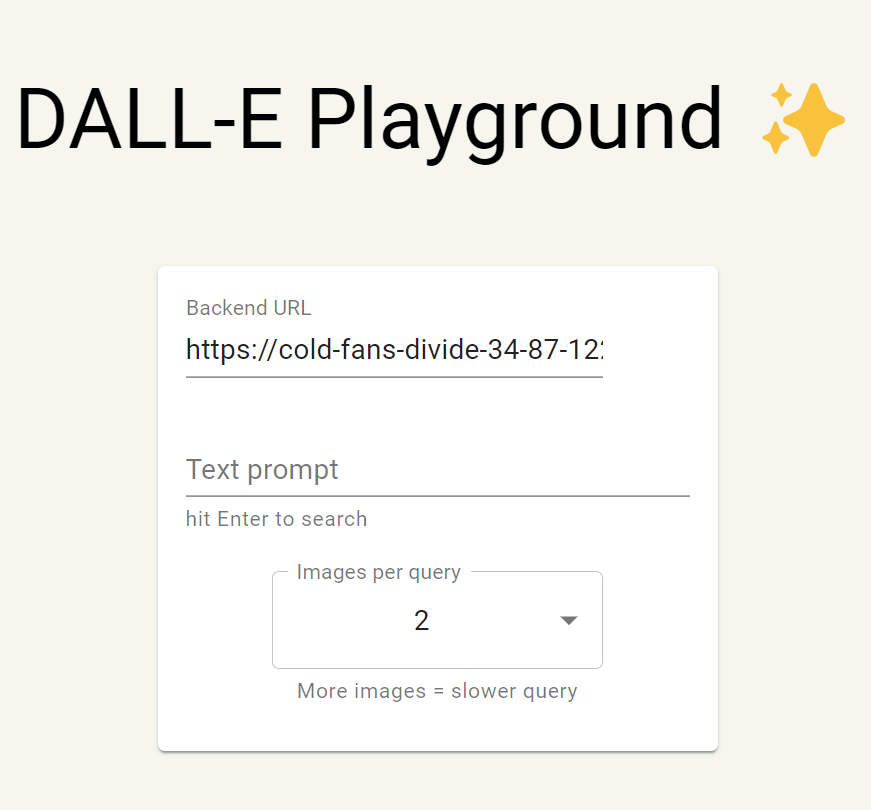
简单来说,官方的text-to-image不公开预训练模型,业界开源的也需要一定资源才可以,所以这个项目就是让大家可以简单的使用业界已经开源好的内容,创建了一个可视化的界面让大家使用。我体验了一把,相当简单。
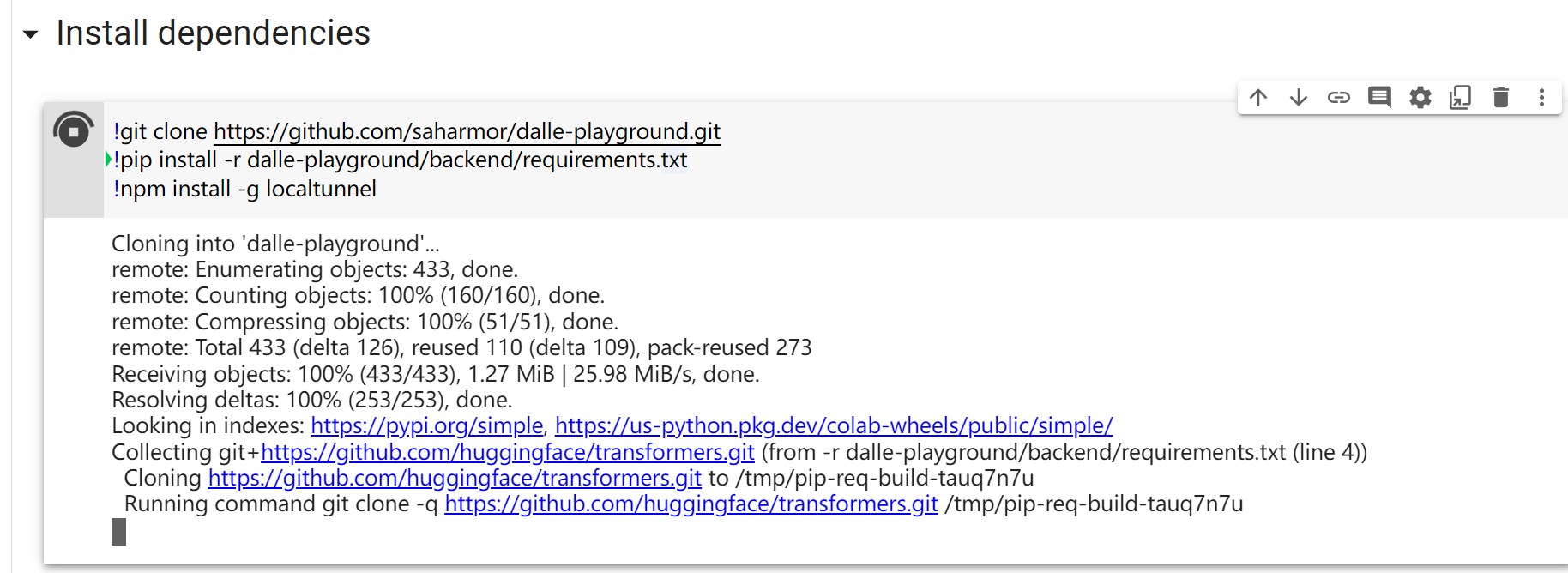
一、复制代码到colab
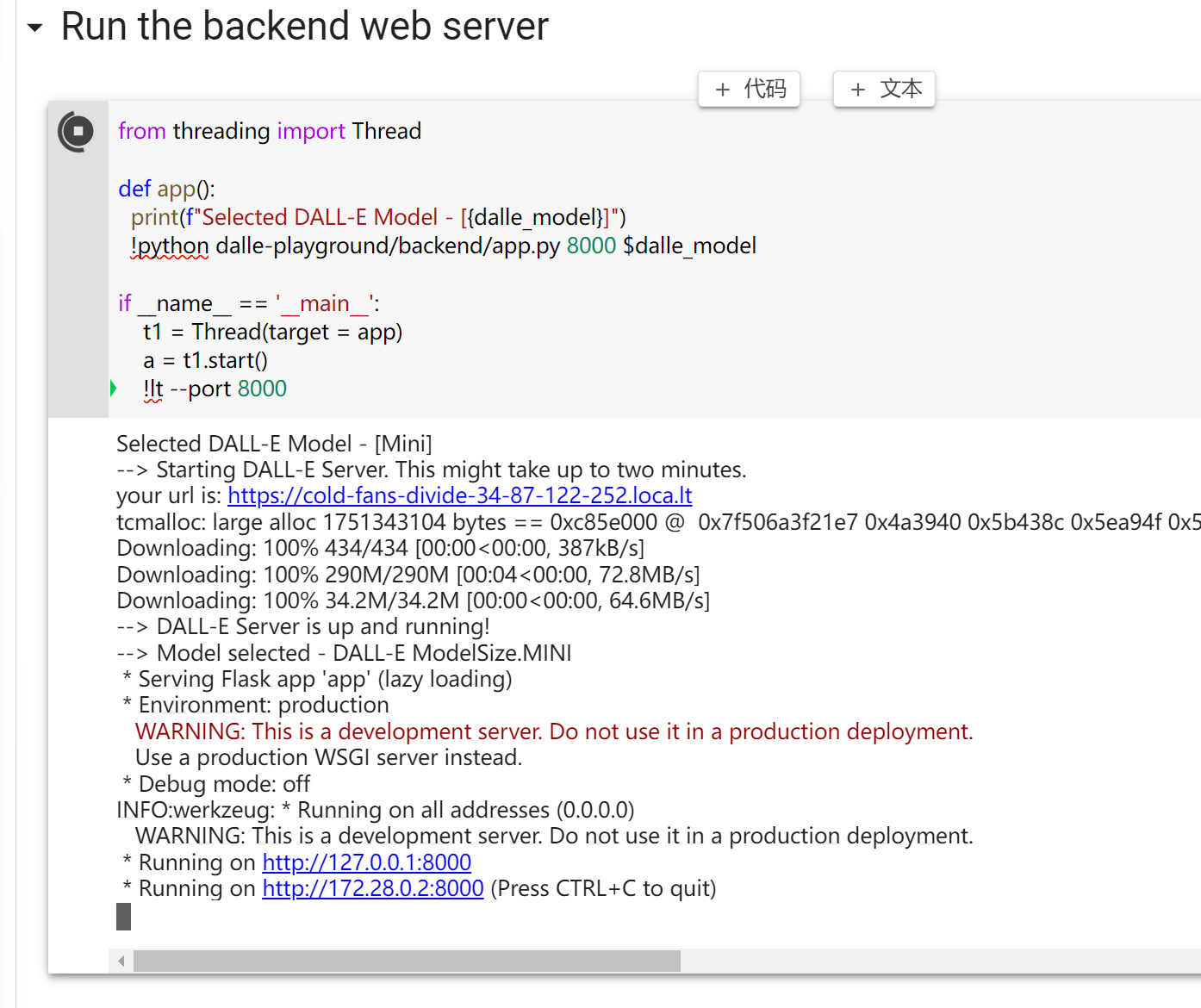
这个项目支持在谷歌Colab免费版本或者你自己机器上载入公开的预训练结果。目前可用的版本包括DALL-E Mini、DALL-E Mega和DALL-E Mega Full。需要的资源如下: