FrontierMath:AI大模型高级数学推理评测的新基准
FrontierMath是一个由Epoch AI开发的基准测试套件,包含数百个原创的数学问题。这些问题由专家数学家设计和审核,覆盖现代数学的主要分支,如数论、实分析、代数几何和范畴论。每个问题通常需要相关领域研究人员投入数小时至数天的努力来解决。基准采用未发表的问题和自动化验证机制,以减少数据污染风险并确保评估可靠性。当前最先进的AI模型在该基准上的解决率低于2%,这反映出AI在处理专家级数学推理时的局限性。该基准旨在为AI系统向研究级数学能力进步提供量化指标。
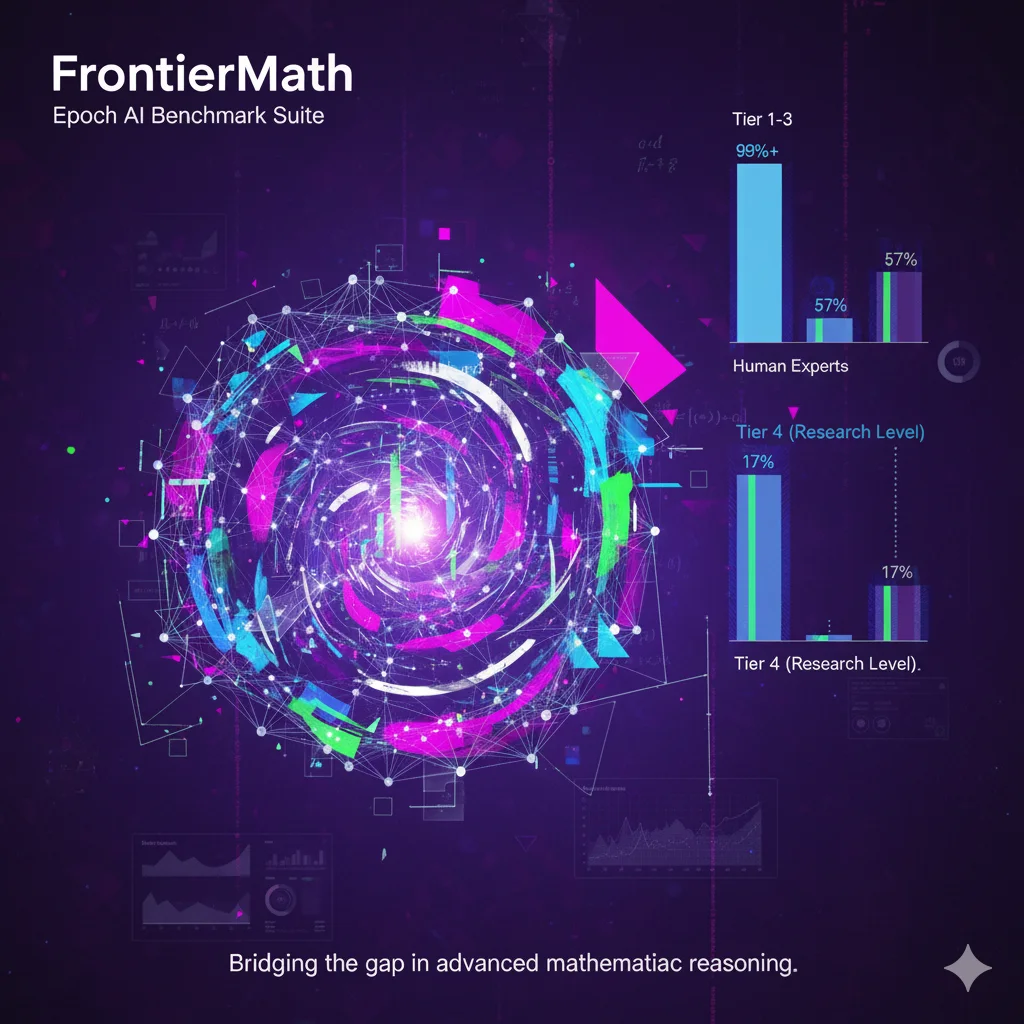
目前,FrontierMath分为2个不同版本的评测,Tier1-3是属于本科阶段的数学水平,具体排行数据参考DataLearnerAI的FrontierMath排行榜:https://www.datalearner.com/benchmarks/frontier-math FrontierMath Tier 4是研究生级别的数学问题,具体数据参考DataLearnerAI的FrontierMath - Tier4的排行榜:https://www.datalearner.com/benchmarks/frontier-math-tier-4
[toc]
当前数学AI评测的局限性
现有数学基准如GSM-8K和MATH已接近饱和状态,领先AI模型在这些测试上的准确率超过90%。这导致评估结果难以区分模型间的细微差异。同时,数据污染成为常见问题,许多模型通过训练数据间接接触到基准内容,从而夸大性能。此外,这些基准多聚焦于本科水平任务,缺少要求多步精确推理和领域专长的挑战性问题。数学作为严谨且可自动验证的领域,本应成为测试复杂科学推理的理想选择,但当前缺乏能反映专家级努力的测试套件。
FrontierMath基准概述
FrontierMath由Epoch AI于2024年11月7日首次发布于arXiv(论文ID: 2411.04872),最新版本更新至2025年8月28日。该基准得到OpenAI的支持,后者委托创建了300个问题(其中50个随机保留用于评估)。开发过程涉及超过60位数学家,包括教授、国际数学奥林匹克问题编写者和菲尔兹奖得主,如Terence Tao和Timothy Gowers。
