SWE-bench大模型评测基准介绍:测试大模型在真实软件工程任务中的能力
随着大语言模型(LLM)的快速发展,它们在自然语言处理(NLP)、代码生成等领域的表现已达到前所未有的高度。然而,现有的代码评测基准(如 HumanEval)通常侧重于自包含的、较短的代码生成任务,而未能充分模拟真实世界的软件开发环境。为弥补这一空白,研究者提出了一种全新的评测基准——SWE-Bench,旨在测试 LLM 在真实软件工程问题中的能力。
OpenAI在此基础上做了人工选择,形成了SWE-Bench Verified,当前大多数模型的评测都是基于这个新的评测基准进行,该评测基准的详情和大模型的得分可以参考DataLearnerAI的SWE-Bench Verified排行榜:https://www.datalearner.com/benchmarks/swe-bench%20verified
其它评测参考:https://www.datalearner.com/benchmarks
1. SWE-Bench:真实世界的软件工程评测基准
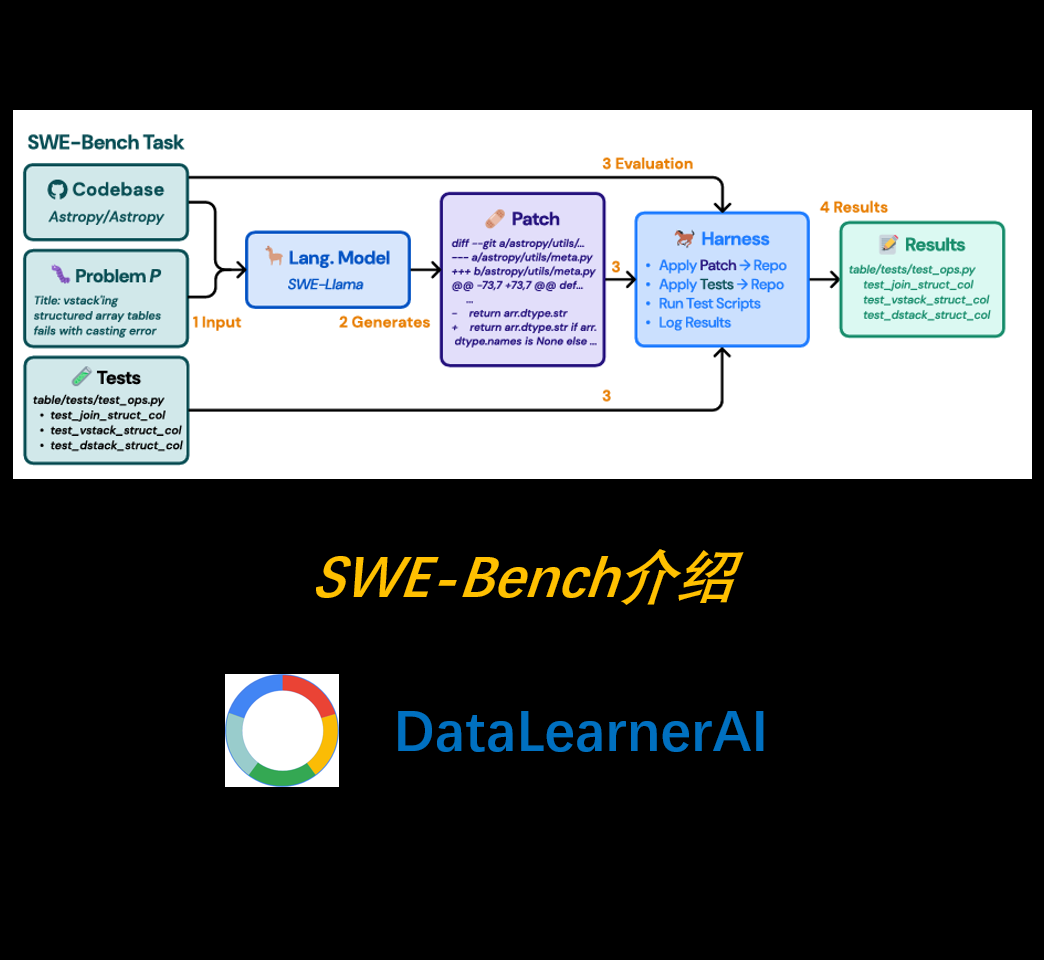
SWE-Bench 由普林斯顿大学和芝加哥大学的研究者提出,并将在 ICLR 2024 会议上发表。该基准聚焦于GitHub 上的实际软件开发问题,其核心任务是让 LLM 解决真实的bug 修复和功能改进问题。具体而言,SWE-Bench 包含 2,294 个任务实例,每个任务都来源于 12 个流行的开源 Python 代码库,涉及真实的GitHub issue 和Pull Request(PR)。
与传统的代码生成评测不同,SWE-Bench 具有以下关键特性:
- 真实世界任务:所有任务均来自 GitHub 代码库,涵盖复杂的代码依赖、跨文件修改等现实开发需求。
- 执行测试评估:模型生成的代码必须成功通过代码库的测试用例,以验证其是否真正解决了问题。
- 长上下文处理:任务涉及的代码库往往包含数千个文件、数十万行代码,远超传统基准的规模。
- 可扩展性:SWE-Bench 可持续更新,未来可以扩展到更多代码库和编程语言。
2. 评测框架:如何构建 SWE-Bench
SWE-Bench 的任务构建流程分为三个主要阶段:
-
数据收集:
- 研究者从 12 个流行的开源 Python 代码库(如 scikit-learn、Django、Matplotlib)中收集了约 90,000 个 PR。
- 选择那些解决 GitHub issue 且修改了测试文件的 PR,确保任务的质量和可评估性。
-
属性筛选:
- 仅保留明确解决某个 issue 且贡献了新的测试用例的 PR。
-
执行筛选:
- 应用 PR 变更并运行测试,确保至少有一个测试从失败(fail)变为通过(pass),以验证 PR 确实解决了相应的问题。
最终,这一过程筛选出了 2,294 个高质量任务实例,涵盖广泛的软件工程问题,如API 变更、性能优化、错误修复等。
3. 任务形式与评测方式
在 SWE-Bench 评测中,每个 LLM 需要完成如下任务:
- 输入:
- GitHub issue 描述(通常包含问题现象、相关代码、复现步骤等)。
- 代码库的当前状态(完整的代码文件)。
- 输出:
- 生成代码补丁(patch),即修改代码库以解决该 issue。
- 评测方式:
- 通过Unix patch 工具应用模型生成的代码补丁,并运行项目的测试套件。
- 如果补丁成功应用且所有相关测试通过,则任务被视为成功解决。
4. 现有大模型的表现
研究者评测了多个最先进的大语言模型,包括 Claude 2、GPT-4、ChatGPT-3.5 和 SWE-Llama(一个基于 CodeLlama 微调的开源模型)。结果显示:
- Claude 2 是表现最好的模型,但其问题解决率仅为 1.96%。
- GPT-4 解决率为 1.31%,SWE-Llama 13B 为 0.70%,ChatGPT-3.5 仅能解决 0.17% 的任务。
- 所有模型的解决率都非常低,表明当前 LLM 在真实软件工程任务中的能力仍然有限。
此外,实验结果表明:
- 任务难度与代码库规模相关:代码库越大,模型的表现越差。
- 跨文件编辑是主要挑战:SWE-Bench 任务的参考解决方案平均涉及 1.7 个文件、3.0 个函数、32.8 行代码,但模型生成的补丁往往较短,且缺乏整体性。
- 检索机制影响显著:当提供模型真实需要修改的文件(oracle retrieval)时,Claude 2 的解决率可提升至 4.8%,表明改进上下文检索是提升表现的关键。
5. SWE-Llama:为 SWE-Bench 任务定制的开源大模型
为进一步探索开源 LLM 在 SWE-Bench 任务上的能力,研究者基于 CodeLlama 进行了微调,并推出了 SWE-Llama(7B 和 13B 版本)。 训练数据:
- 研究者收集了 19,000 个 issue-PR 对 作为训练集,覆盖 37 个流行 Python 代码库。
- 相较于 SWE-Bench 评测集,训练数据不要求 PR 修改测试文件,从而扩大了数据规模。
- 训练采用 LoRA(低秩适配) 进行高效参数微调。
SWE-Llama 结果:
- 在 SWE-Bench 评测中,SWE-Llama 13B 表现接近 Claude 2,但仍受限于上下文选择问题。
- 其生成的补丁仍然较短,难以解决跨文件修改的问题。
6. 未来方向与挑战
SWE-Bench 的评测结果揭示了当前 LLM 在软件工程领域的多个挑战:
-
长上下文理解能力不足:
- 代码库平均包含 400K+ 行代码,模型难以有效检索真正相关的代码部分。
- 需要探索 更高效的代码检索与长上下文建模方法。
-
跨文件、跨模块的推理能力薄弱:
- 真实的软件工程任务往往涉及多个文件、多个函数的修改,但现有 LLM 难以协调全局修改。
- 需要探索 基于多步推理或智能代理(Agent-based) 的方法。
-
代码质量与可读性问题:
- 现有模型生成的补丁往往只解决当前 issue,而忽略代码风格、一致性、潜在副作用。
- 未来可结合 软件工程最佳实践 进行模型优化。
7. 结论
SWE-Bench 作为首个基于真实 GitHub 代码库的大模型评测基准,为 LLM 在软件工程领域的能力提供了严苛的测试环境。实验结果表明,即使是当前最先进的 LLM,其在真实软件开发中的应用仍然面临重大挑战。
未来的研究方向:
- 进一步优化 长上下文建模,提高代码检索的精准度。
- 结合 自动化代码分析工具、智能代理(AI Agent),提升 LLM 的全局推理能力。
- 扩展到更多编程语言(如 Java、C++),构建更全面的代码评测基准。
SWE-Bench 的推出,标志着 LLM 在软件工程领域评测迈入了一个更具挑战性的阶段。未来,随着大模型的不断进步,我们或许能见证真正能够解决复杂软件工程问题的 AI 代码助手的诞生。
