开源领域大语言模型再上台阶:Databricks开源1320亿参数规模的混合专家大语言模型DBRX-16×12B,评测表现超过Mixtral-8×7B-MoE,免费商用授权!
1,323 阅读
基于混合专家技术的大语言模型是当前大语言模型的一个重要方向。去年MistralAI开源了全球最有影响力的Mixtal-8×7B-MoE模型,吸引了很多关注。在2024年3月27日的今天,Databricks宣布开源一个全新的1320亿参数的混合专家大语言模型DBRX。
DBRX简介
DBRX是Databricks开源的一个transformer架构的大语言模型。包含1320亿参数,共16个专家网络组成,每次推理使用其中的4个专家网络,激活了360亿参数。
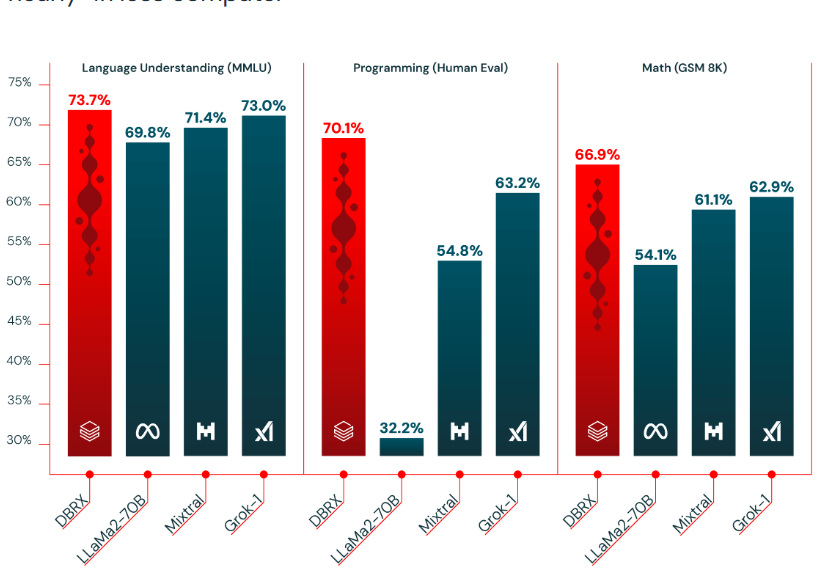
它与业界著名的混合专家网络模型对比结果如下:
| 模型信息 | 总参数数量 | 专家网络数目 |推理使用参数量 | 模型信息卡地址| | ------------ | ------------ | ------------ | ------------ | |DBRX | 1320 | 16 | 360 | https://www.datalearner.com/ai-models/pretrained-models/DBRX-Instruct| |Mixtral-8×7B-MoE | 467 | 8 | 120 | https://www.datalearner.com/ai-models/pretrained-models/Mistral-7B-MoE | | Grok-1 | 3140 | 8 | 860 | |DeepSeekMoE-16B | 164 | 8 | 28| |

