MistralAI的混合专家大模型Mistral-7B×8-MoE详细介绍,效果超过LLaMA2-70B和GPT-3.5,推理速度快6倍
1,738 阅读
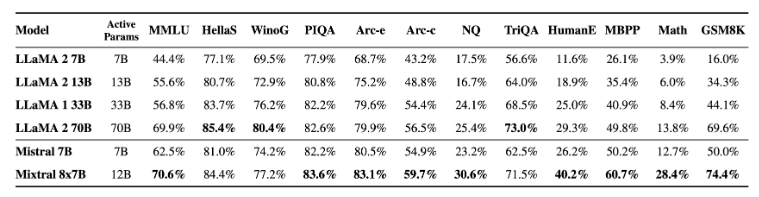
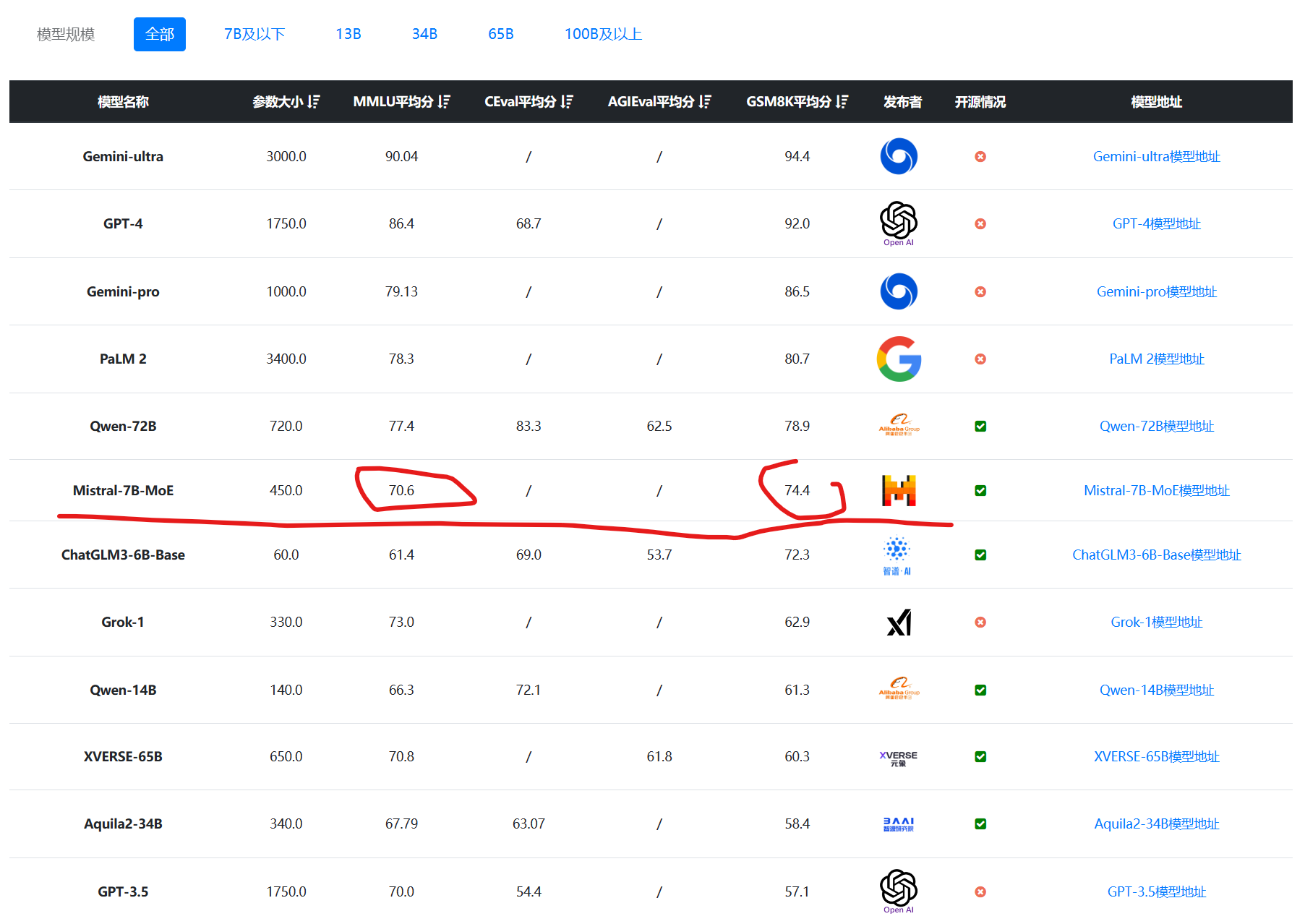
12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)(详情参考DataLearnerAI此前的介绍:MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。

Mistral-7B×8-MoE的特点
根据官方的介绍,Mistral-7B×8-MoE是一个高质量稀疏型的专家混合模型。是8个70亿参数规模大模型的混合。它的主要特点如下:
- 它可以非常优雅地处理32K上下文数据
- 除了英语外,在语表现也很好