MistralAI正式官宣开源全球最大的混合专家大模型Mixtral 8x22B,官方模型上架HuggingFace,包含指令微调后的版本!
1,727 阅读
MistralAI是法国的一家人工智能大模型初创企业,他们开源的Mistral系列大模型获得了非常多的好评。此前,他们开源的全球最有影响力的Mixtral 8×7B-MoE模型开启了全球的MoE大模型的潮流。在四个月之后的2024年4月10日,MistralAI在推特上发出了一个磁力链接,大家下载之后发现这是全新的Mixtral 8x22B模型,一周后的今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
Mixtral-8x22B模型基本信息
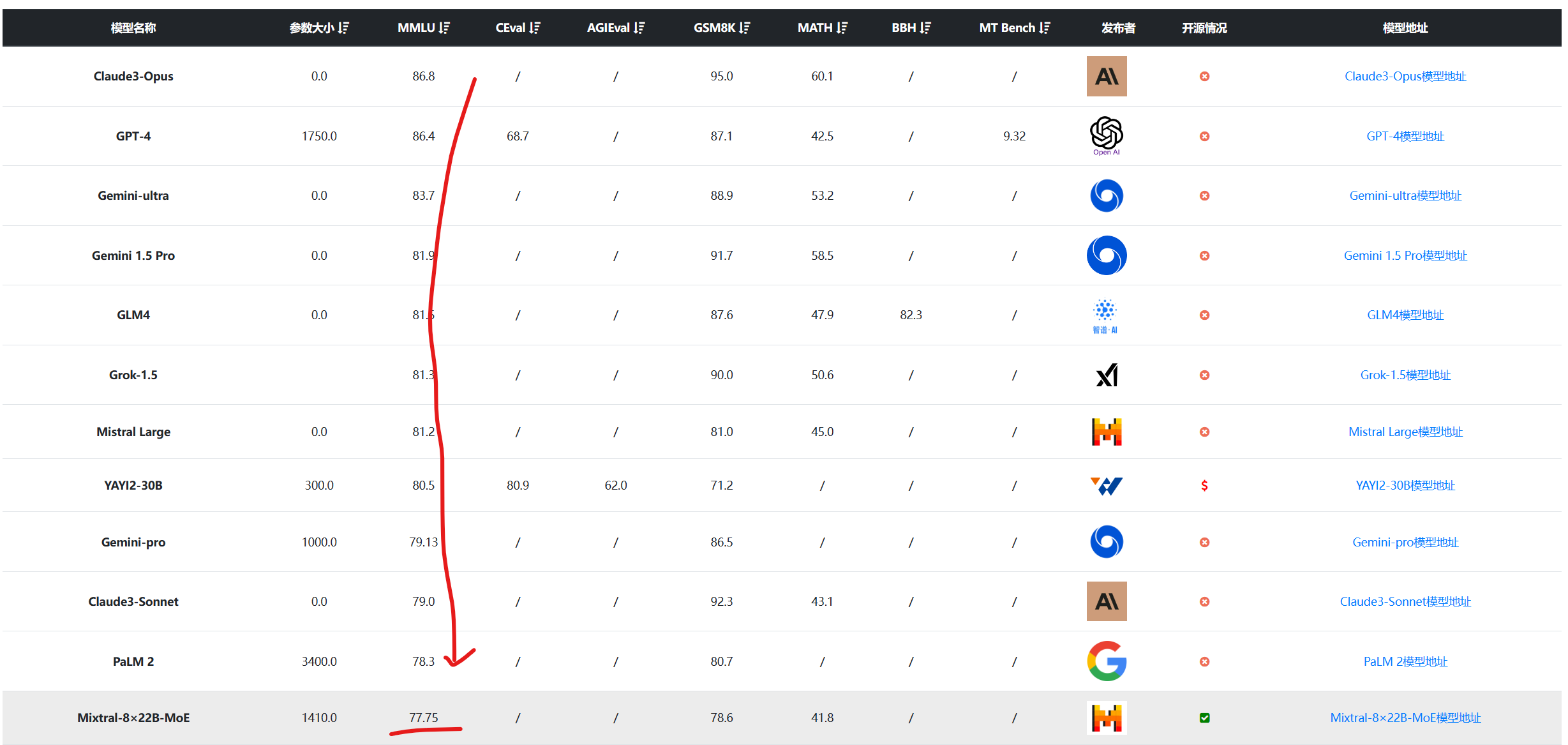
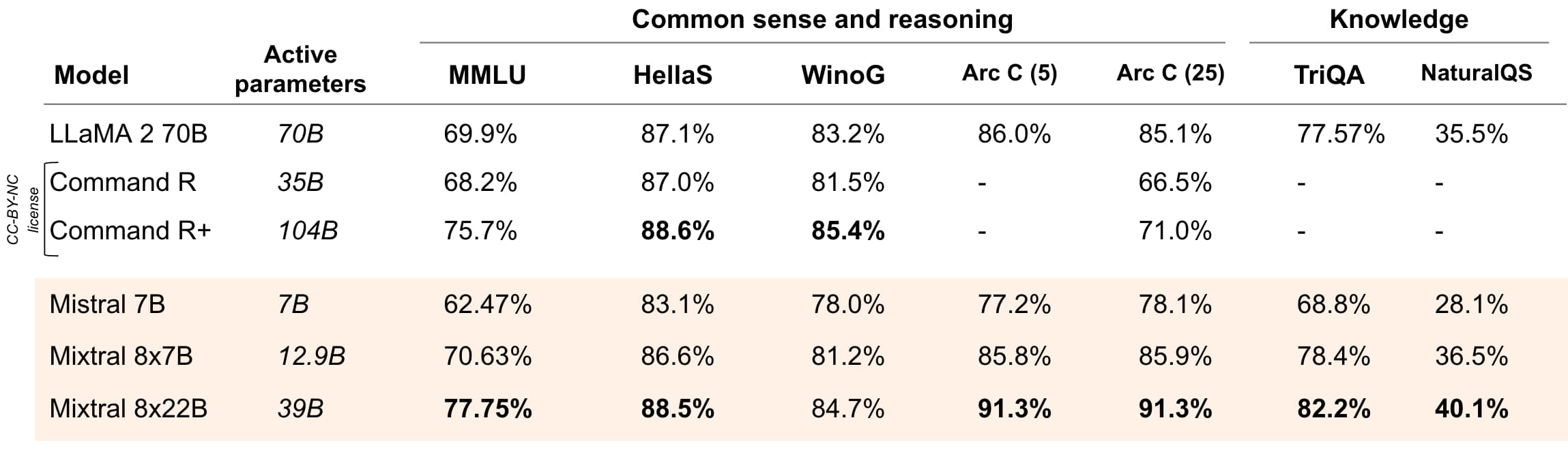
Mixtral-8x22B模型是一个稀疏混合专家大模型(sparse Mixture-of-Experts,SMoE),总参数量1410,每次推理激活其中的390亿参数。
Mixtral-8x22B的主要特点总结如下:
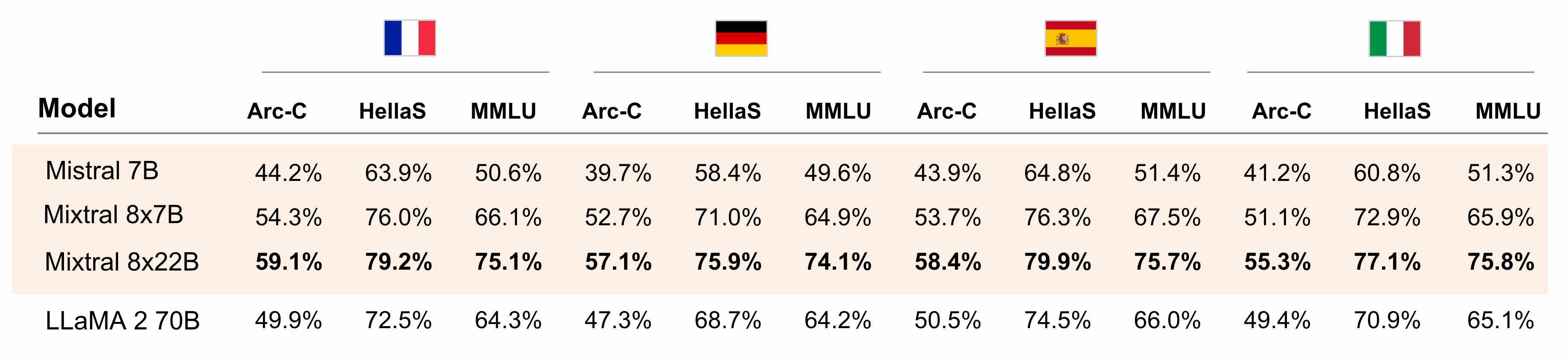
- 支持多语言,在英语、法语、意大利语、德语和西班牙语上非常流程(实际测试也能支持基本的中文)
- 数学推理和代码能力大幅提升
- 天然支持function calling特性
- 支持64K超长上下文
- Apache2.0开源协议,真正的开源
这里顺便说一下,虽然MetaAI开源了Llama系列大模型,但是他们最新的开源协议增加了遵守贸易合规的条款,这意味着很多中国企业可能无法使用!而Mixtral 8x22B模型的Apache2.0可以理解为真正的可商用的开源协议,几乎没有限制使用!
Mixtral 8x22B模型的效果
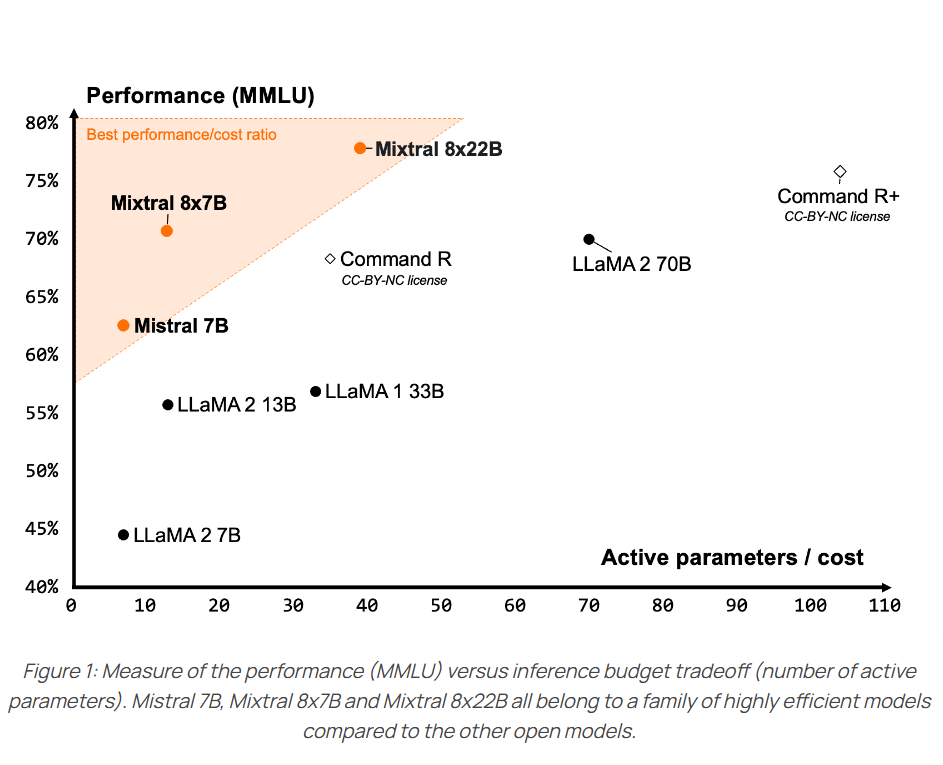
Mixtral 8x22B模型是混合专家模型,因此它的推理显存大小要求和参数总规模是一致的,即1410亿参数,大约需要280GB显存,不会有优势。但是推理只激活其中的390亿参数,意味着这个模型的推理速度方面与390亿参数规模模型差不多。下图是官方展示的对比结果: