准备迎接超级人工智能系统,OpenAI宣布RLHF即将终结!超级对齐技术将接任RLHF,保证超级人工智能系统遵循人类的意志
1,073 阅读
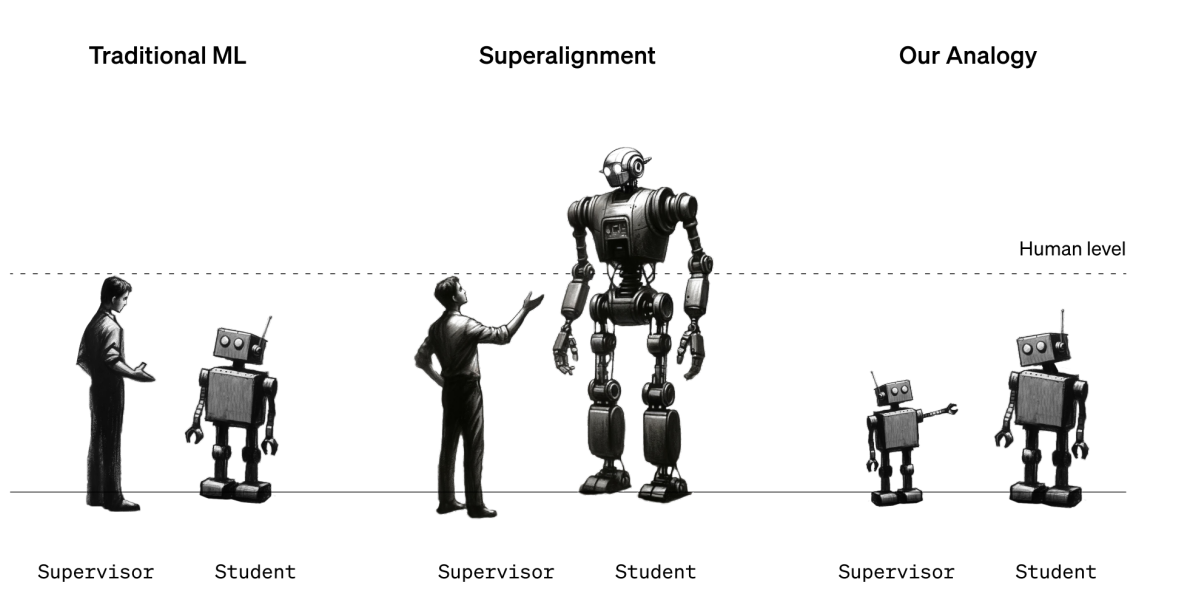
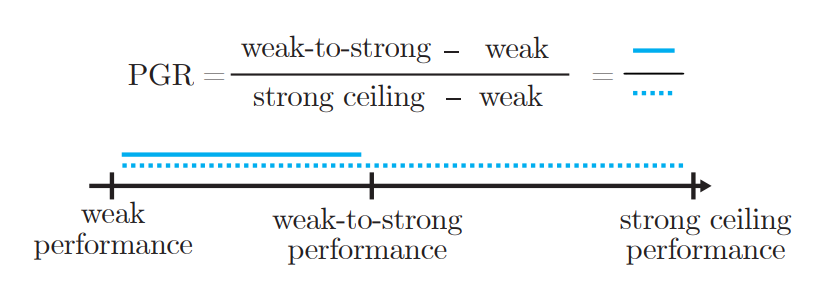
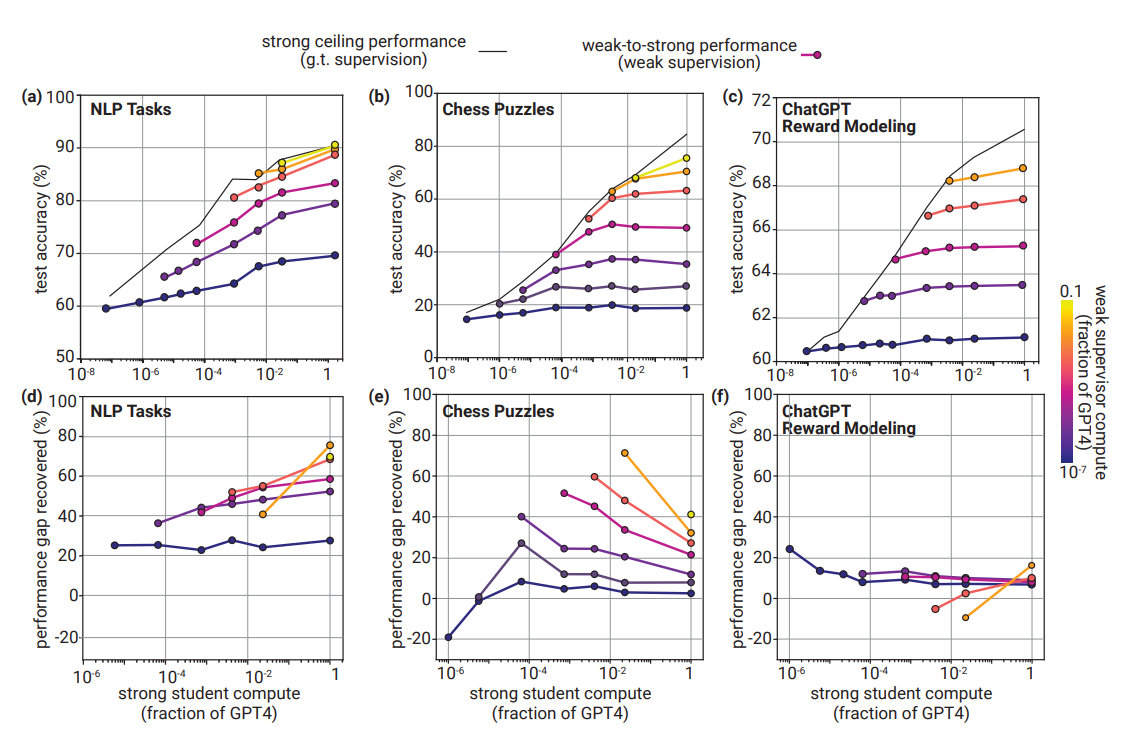
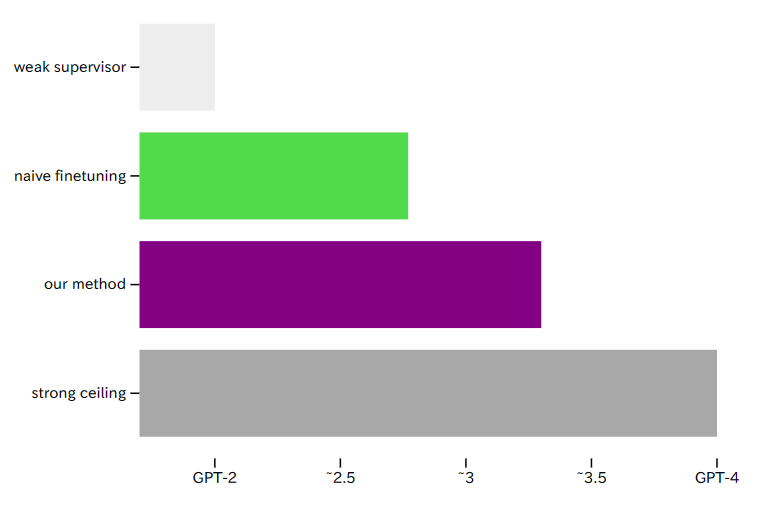
今天,OpenAI在其官网上发布了一个全新的研究成果:一个利用较弱的模型来引导对齐更强模型的能力的技术,称为由弱到强的泛化。OpenAI认为,未来十年来将诞生超过人类的超级AI系统。但是,这会出现一个问题,即基于人类反馈的强化学习技术将终结。因为彼时,人类的水平不如AI系统,所以可能无法再对模型输出的内容评估好坏。为此,OpenAI提出这种超级对齐技术,希望可以用较弱的模型来对齐较强的模型。这样可以在出现比人类更强的AI系统之后可以继续让AI模型可以遵循人类的意志、偏好和价值观。

RLHF技术及其问题
RLHF全称Reinforcement Learning from Human Feedback,是当前大语言模型在微调之后必不可少的一个步骤。简单来说,就是让模型输出结果,人类提供结果反馈,然后模型学习理解哪些输出是更好的,这里所说的更好包括道德、价值观以及回复质量等。
在此前Microsoft Build 2023上,来自OpenAI的研究员分享了ChatGPT是如何被训练出来的,那次汇报他回答了为什么大模型在做了有监督微调之后还要做RLHF,这不单单是一个价值对齐的训练,而且是因为它会让模型的回复质量变得更高。至于原因,其实并不是很明确(详情参考:来自Microsoft Build 2023:大语言模型是如何被训练出来的以及语言模型如何变成ChatGPT——State of GPT详解)。