语音大模型正式进入Voice Agent时代!OpenAI发布GPT Realtime模型,可以直接调用接口和工具进行实时语音对话!
621 阅读
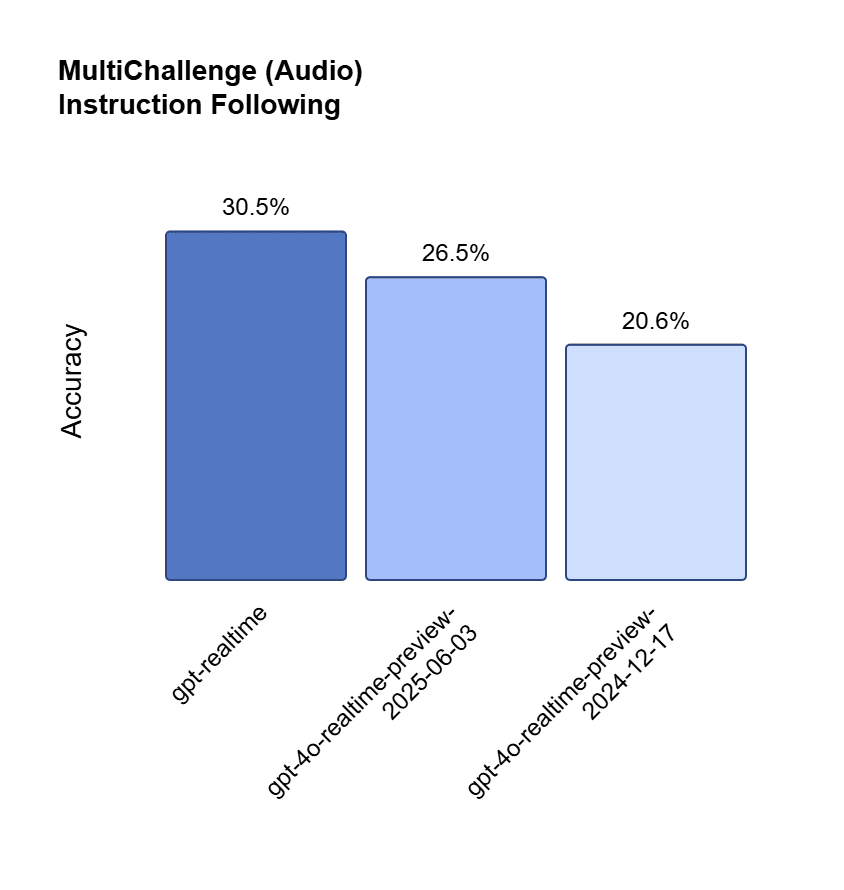
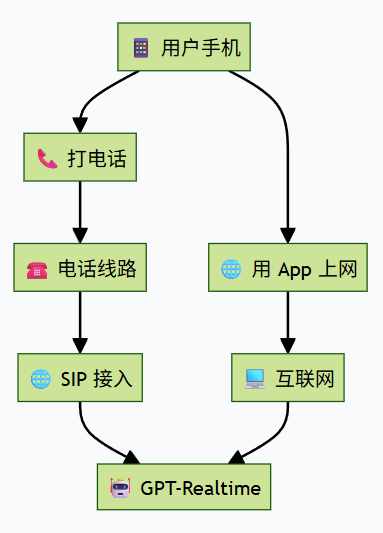
就在几个小时前,OpenAI 发布了全新的 GPT Realtime 大模型。这是一个 Speech-to-Speech(S2S)模型,能通过单个模型与 API完成从音频输入到音频输出的全流程,显著降低交互延迟并充分保留语音细节。 GPT Realtime 以“端到端语音理解—推理—合成”为核心路径,解决了传统“识别—推理—合成”多阶段带来的延迟与风格割裂问题。

GPT Realtime:定位、来历与能力特点
OpenAI 早在 2024 年 10 月就推出过首个 S2S 模型(),随后在 2024-12-17 与 2025-06-03 又有两次预览迭代,但它们均基于 GPT-4o 架构、且仍处于 preview 阶段,反馈包括、**跨语种回复混乱(如德语回答英文问题)**等。