大模型如何使用长上下文信息?斯坦福大学最新论文证明,你需要将重要的信息放在输入的开始或者结尾处!
6,114 阅读
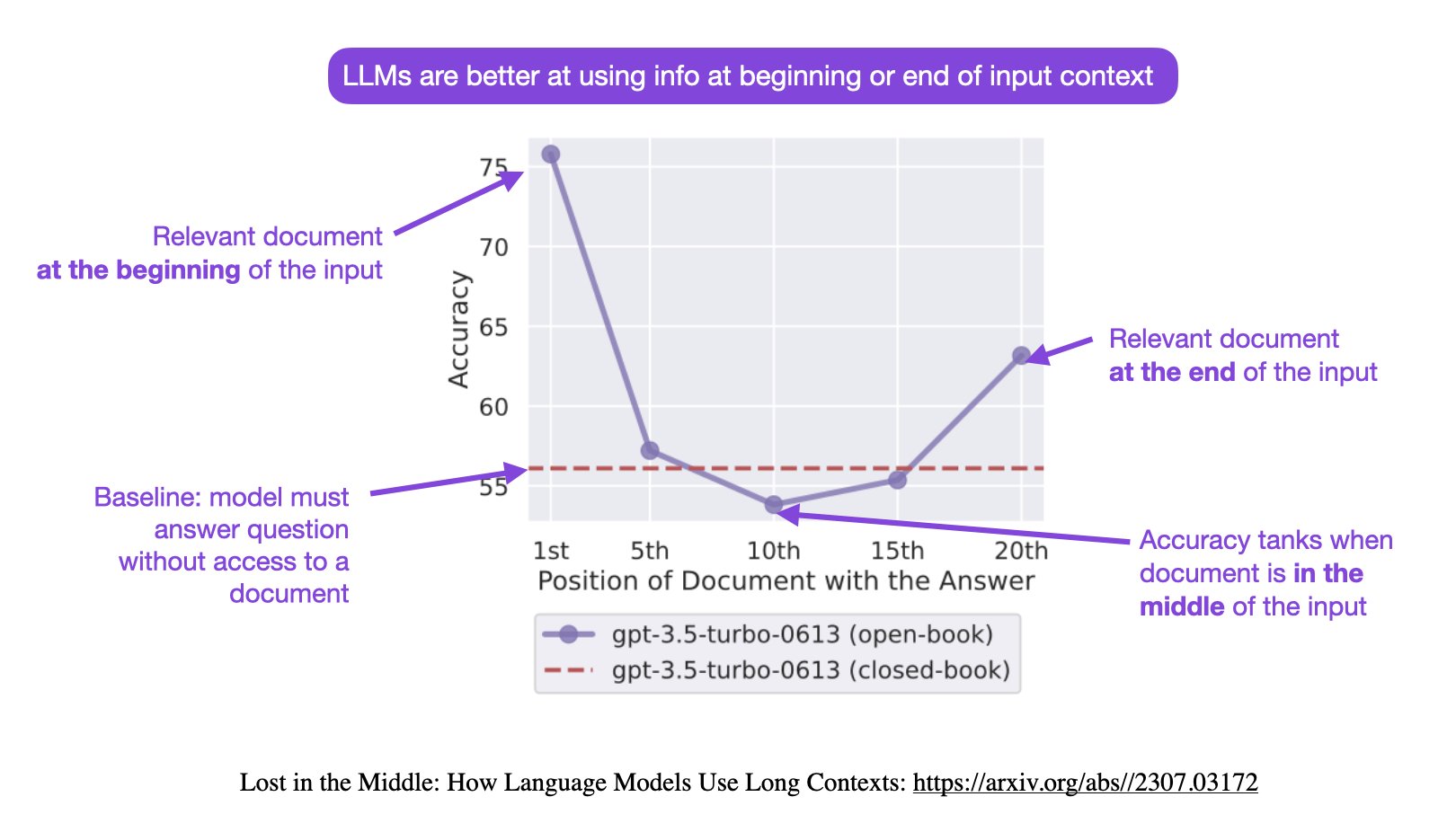
大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。

这篇论文名字是Lost in the Middle: How Language Models Use Long Contexts,本文介绍其核心观点。
当前大模型处理长输入的水平依然不够
在大语言模型(Large Language Model,LLM)中,"上下文长度"是指大语言模型在生成预测时考虑的输入文本的长度。上下文长度对于语言模型的性能有着重要的影响。一般来说,更长的上下文长度可以让模型看到更多的信息,从而做出更准确的预测。
然而,处理更长的上下文也需要更多的计算资源,这可能会限制模型的实用性。而且,在实际应用中,大多数模型在处理长输入的时候都发生了性能显著下降的情况。
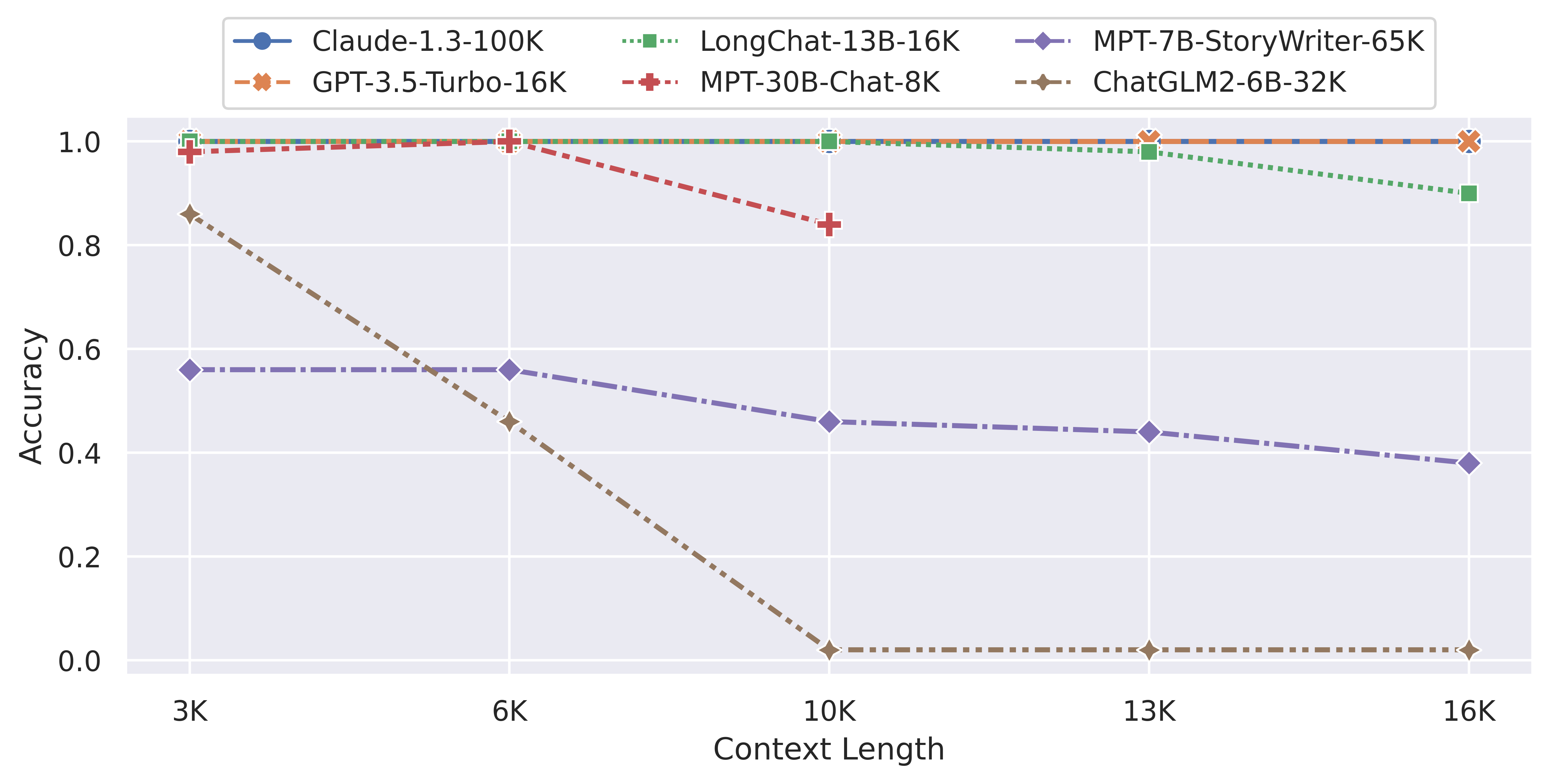
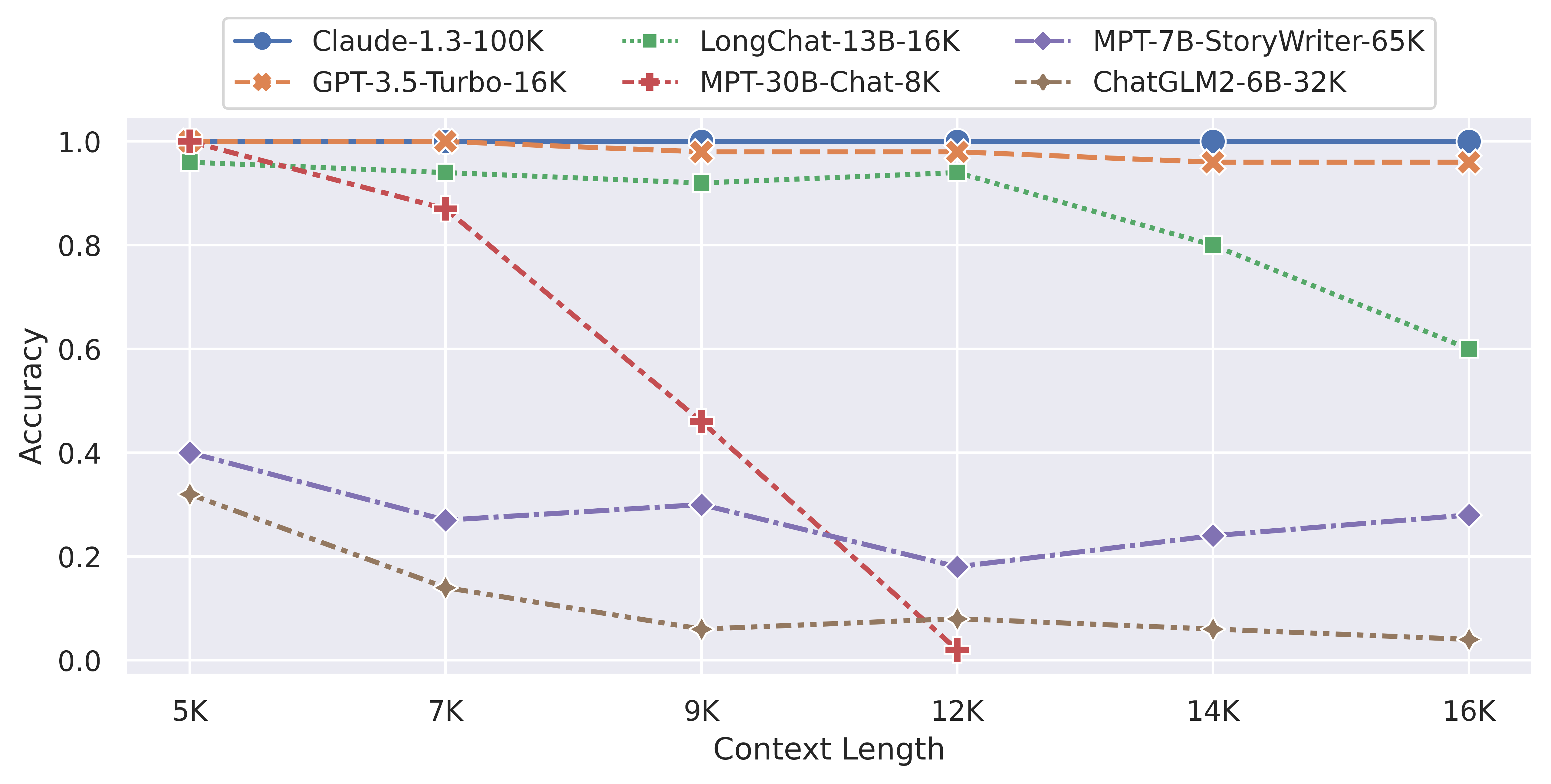
例如,在上周的LM-SYS公布的长输入评测中,各个开源模型都遭遇了非常严重的问题(参考:支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3)。