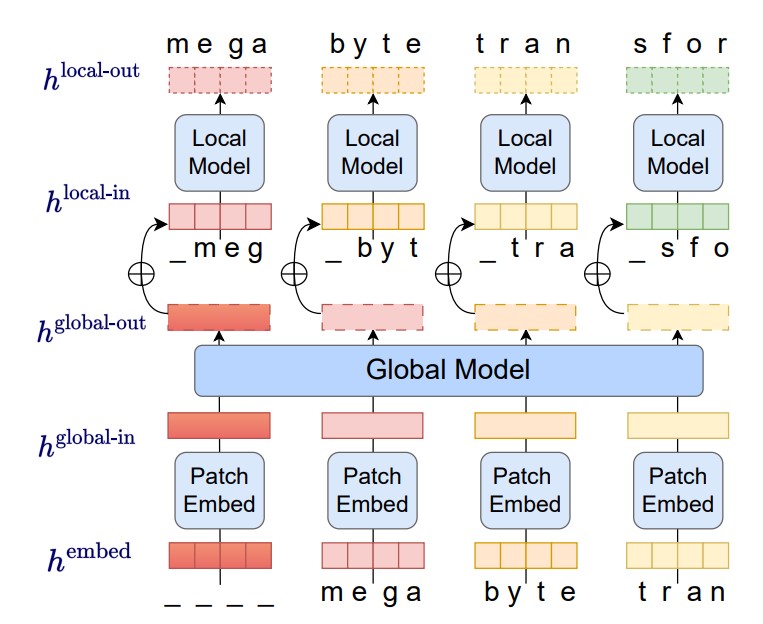
解决大语言模型的长输入限制:MetaAI发布MegaByte最高支持几百万上下文输入!
3,962 阅读
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!

本文将简单介绍这个方法!论文名称:《MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers》。
transformer模型的输入限制问题
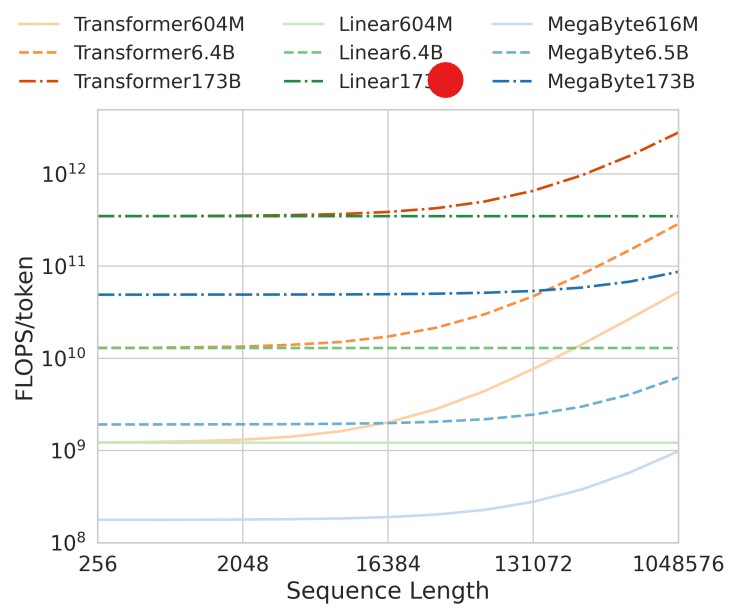
尽管目前的大语言模型在较短序列(几千个tokens以内)的应用场景下有着惊人的效果,但是数百万序列的输入依然是一种刚需,包括音乐、图片、视频、小说、代码等,它们的输入长度通常都是远远超过当前大语言模型的输入限制。主要原因是自注意力机制的“成本”随着输入成二次方增长,以及每个位置都需要计算大型的前馈网络。
借用Raimi Karim博客里面的示意图如下:
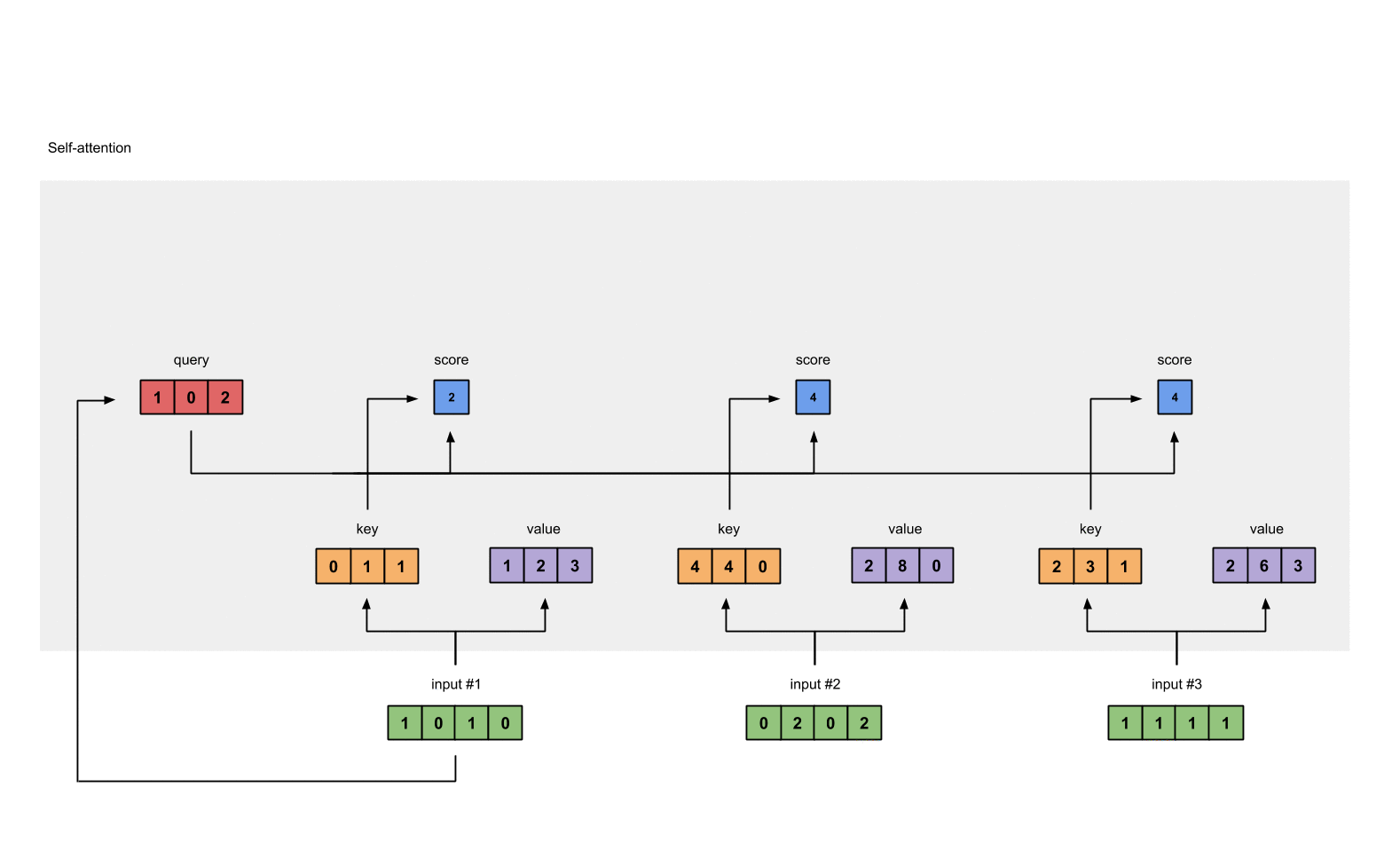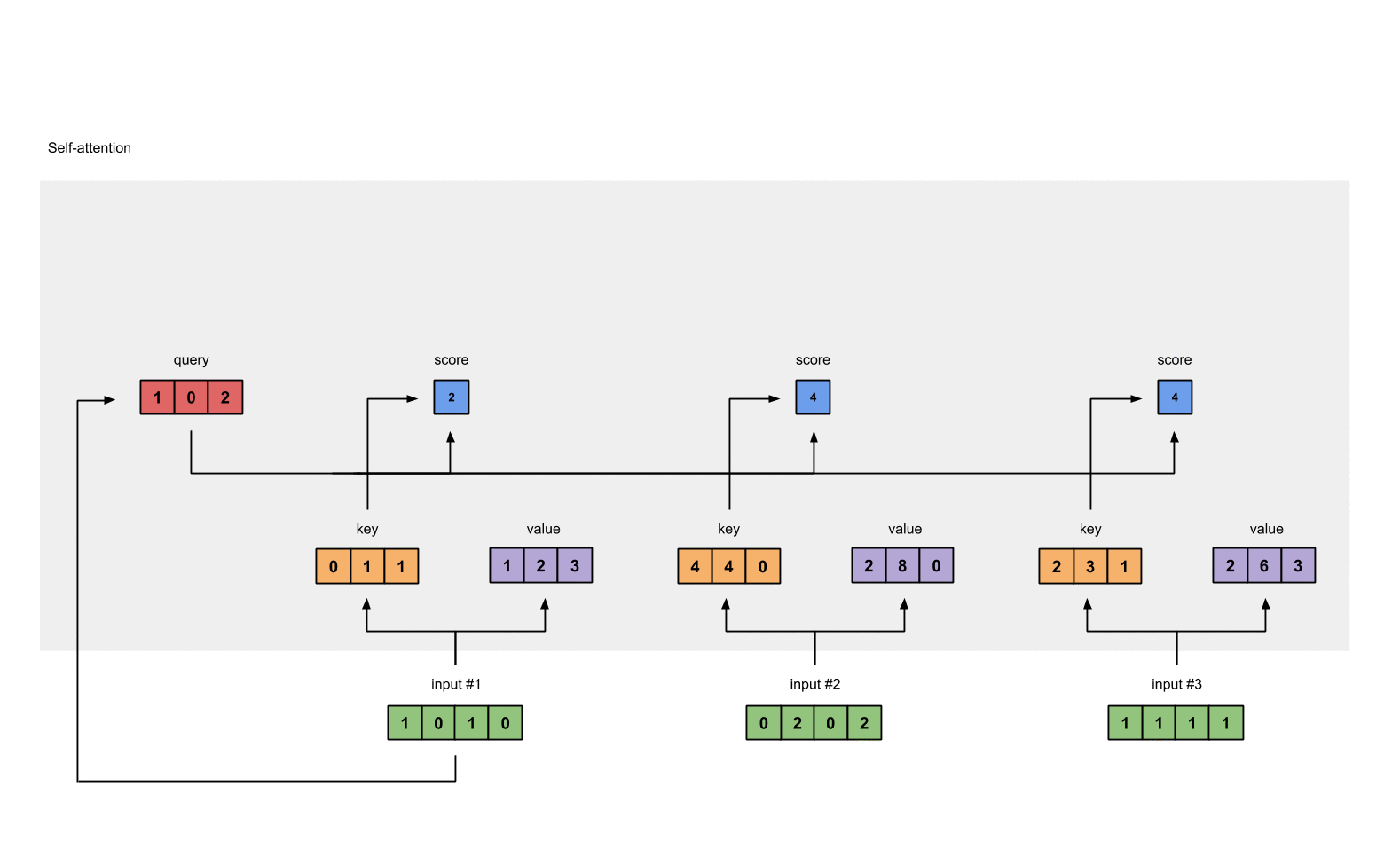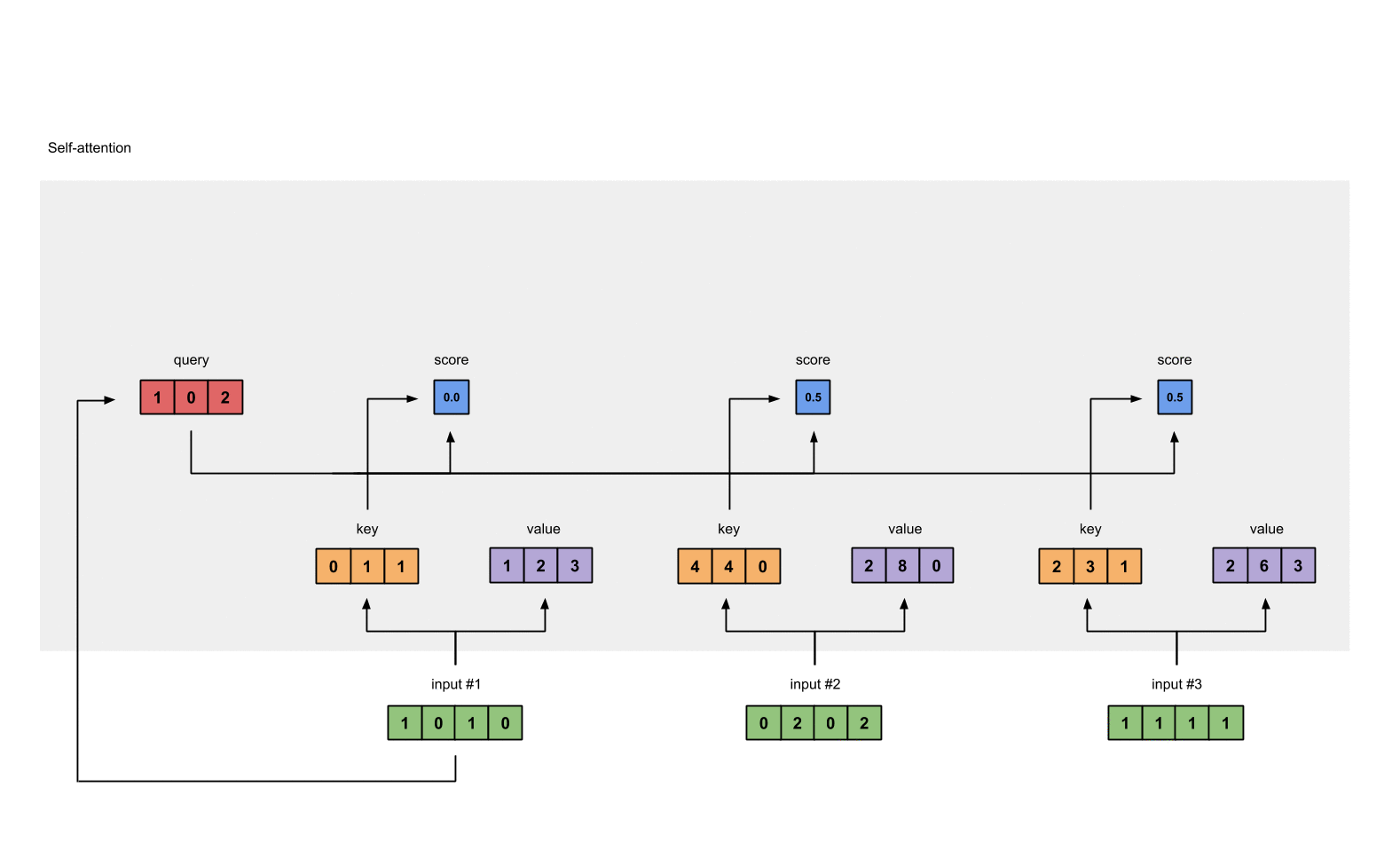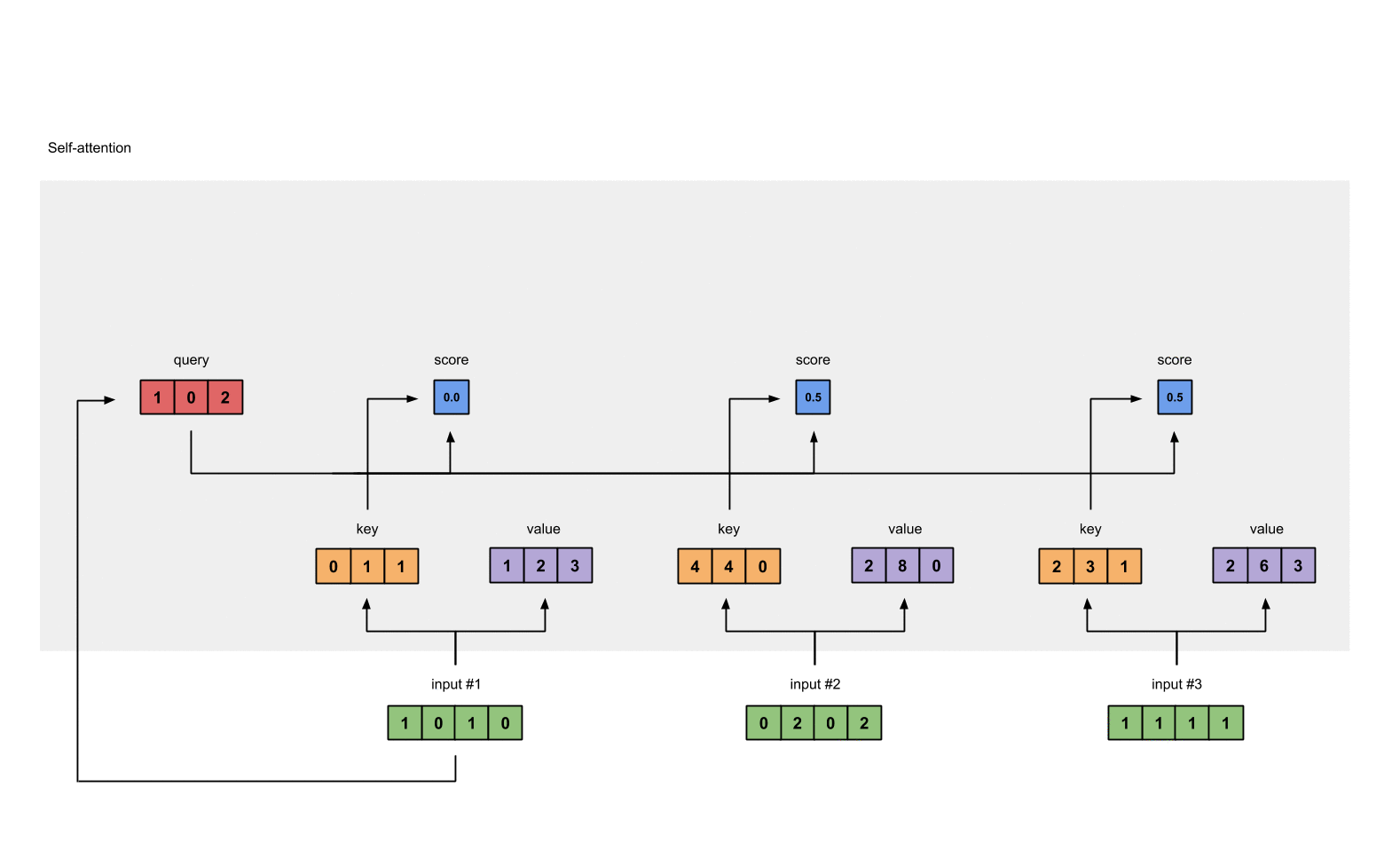
可以看到,在自注意力计算中,输入序列的每一个位置都要与其它位置计算得分,因此,对于输入为$n$的transformer模型来说,它的计算复杂度是$\mathcal{O}(n^2)$。尽管之前也有很多方法提出了一些很有效率的注意力机制,但是长序列建模最大的问题其实是每个位置都要计算巨大的前馈网络。这是其中最费时间的!
而本次MetaAI提出的这个方法,计算复杂度只有$\mathcal{O}(n^{4/3})$。其未来的应用前景巨大!