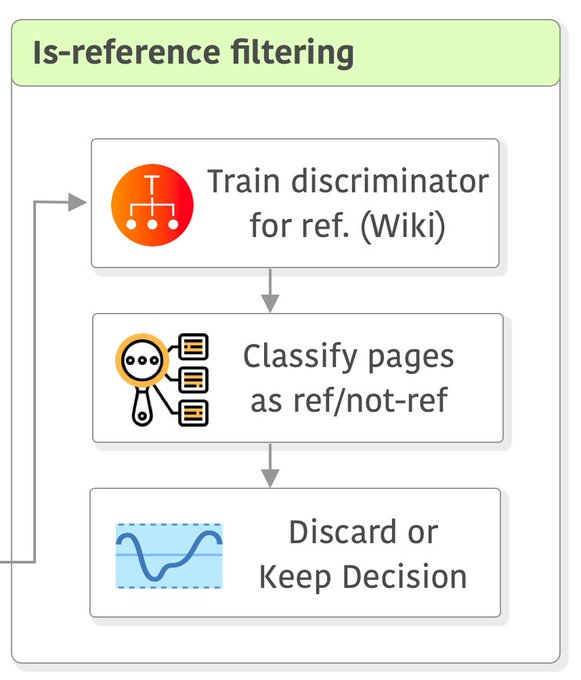
大语言模型训练之前,数据集的处理步骤包含哪些?以LLaMA模型的数据处理pipeline(CCNet)为例
5,317 阅读
大语言模型的训练是一个十分复杂的技术,不仅涉及到模型的开发与部署,还涉及到数据的获取。与常规的算法模型不同的是,大语言模型通常需要大量的数据处理步骤。本文是根据英国一位自动工程师总结的大语言模型训练之前的数据处理步骤和决策过程。
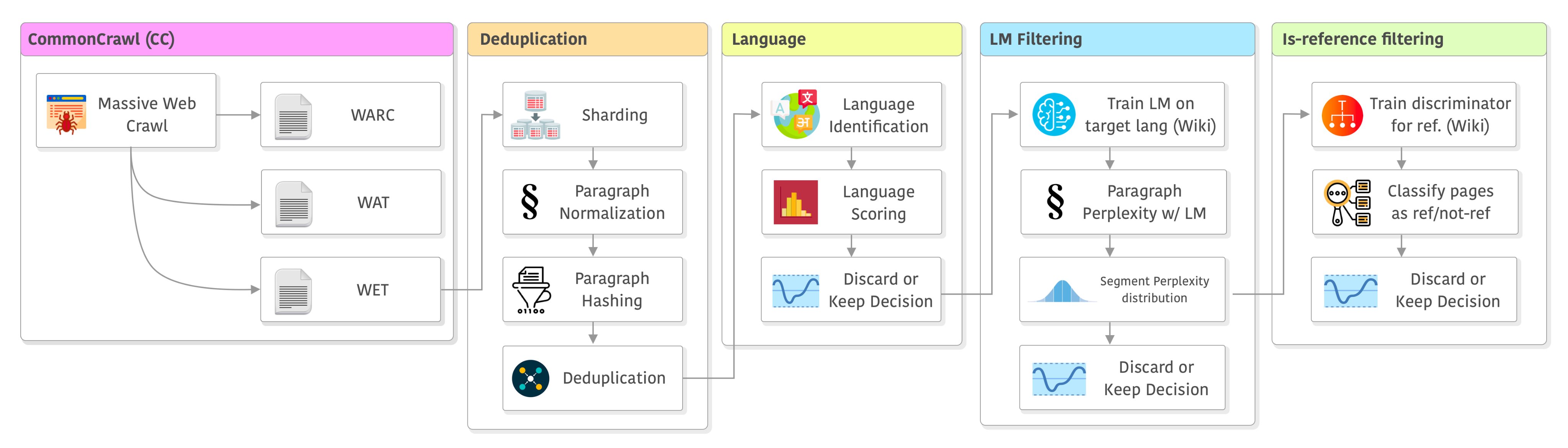
该总结主要来源MetaAI发布的LLaMA模型的论文。同时,也会增加我自己做的一些说明。LLaMA是MetaAI开源的大语言模型,也是近期发布的很多模型的基础模型。CCNet是LLaMA模型使用的数据处理pipeline。关于LLaMA模型在DataLearner官方的模型信息卡参考:https://www.datalearner.com/ai-models/pretrained-models/LLaMA
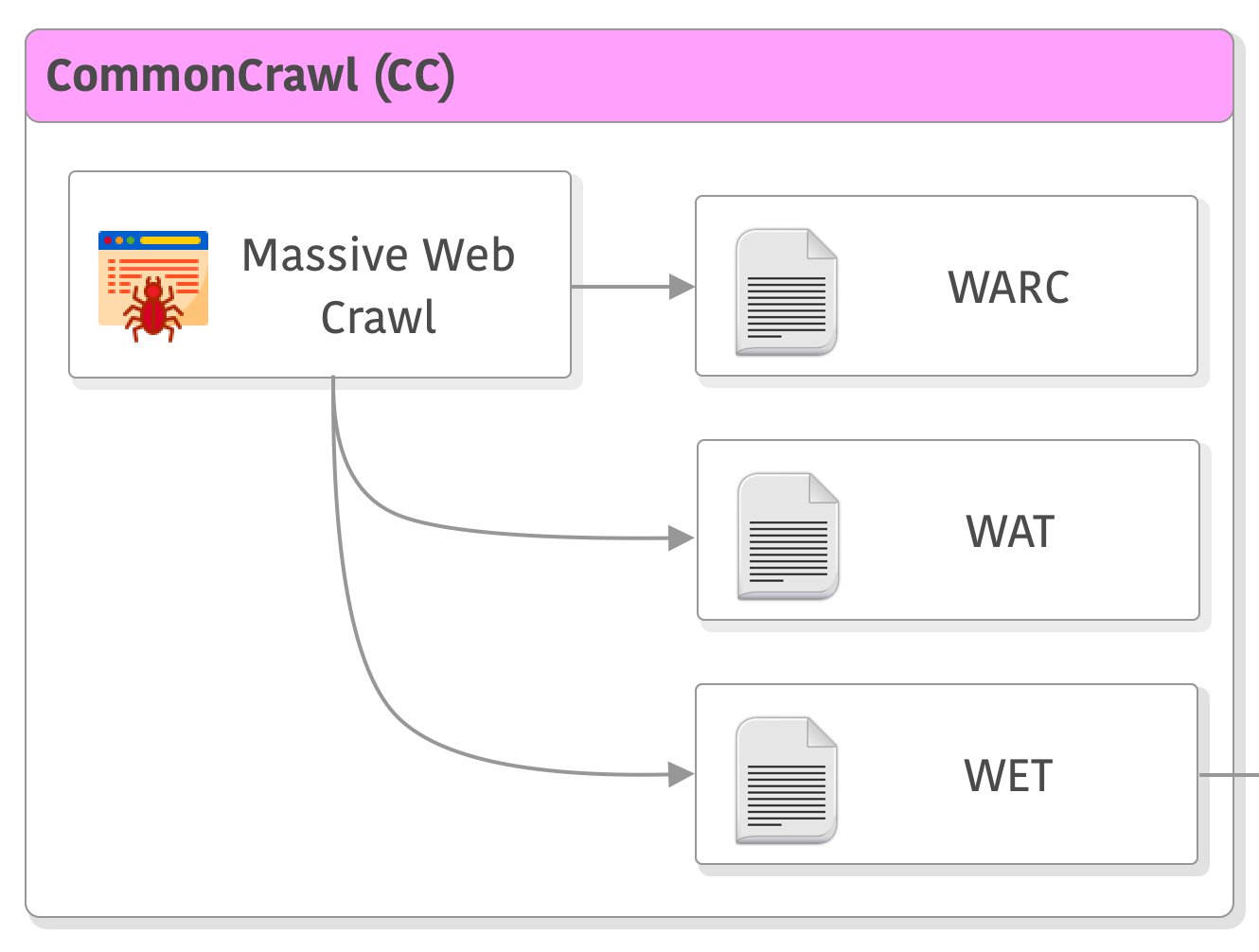
一、数据爬取和保存
大语言模型的训练需要大量的数据,为了获取更多的数据训练,当前大语言模型的训练都以无标注的数据为主。以LLaMA为例,它们获取的数据如下: