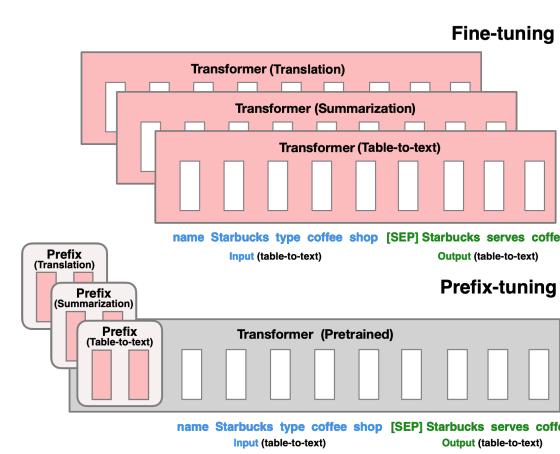
预训练大语言模型的三种微调技术总结:fine-tuning、parameter-efficient fine-tuning和prompt-tuning
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型(BERT在DataLearner官方模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/BERT )的时候,大家还没有意识到本轮AI浪潮会发展到如此火热的地步。但是,BERT出现之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。
当然,这三种技术并不是有完全隔离的界线,目前很多研究也并没有明显区分,本文的内容结合部分研究提供一种视角。欢迎理性讨论~
一、fine-tuning技术
Fine-tuning是一种在自然语言处理(NLP)中使用的技术,用于将预训练的语言模型适应于特定任务或领域。Fine-tuning的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它。
Fine-tuning的概念已经存在很多年,并在各种背景下被使用。Fine-tuning在NLP中最早的已知应用是在神经机器翻译(NMT)的背景下,其中研究人员使用预训练的神经网络来初始化一个更小的网络的权重,然后对其进行了特定的翻译任务的微调。
经典的fine-tuning方法包括将预训练模型与少量特定任务数据一起继续训练。在这个过程中,预训练模型的权重被更新,以更好地适应任务。所需的fine-tuning量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的fine-tuning。如果两者不相似,则可能需要更多的fine-tuning。
在NLP中,fine-tuning最著名的例子之一是由OpenAI开发的OpenAI GPT(生成式预训练变压器)模型。GPT模型在大量文本上进行了预训练,然后在各种任务上进行了微调,例如语言建模,问答和摘要。经过微调的模型在这些任务上取得了最先进的性能。
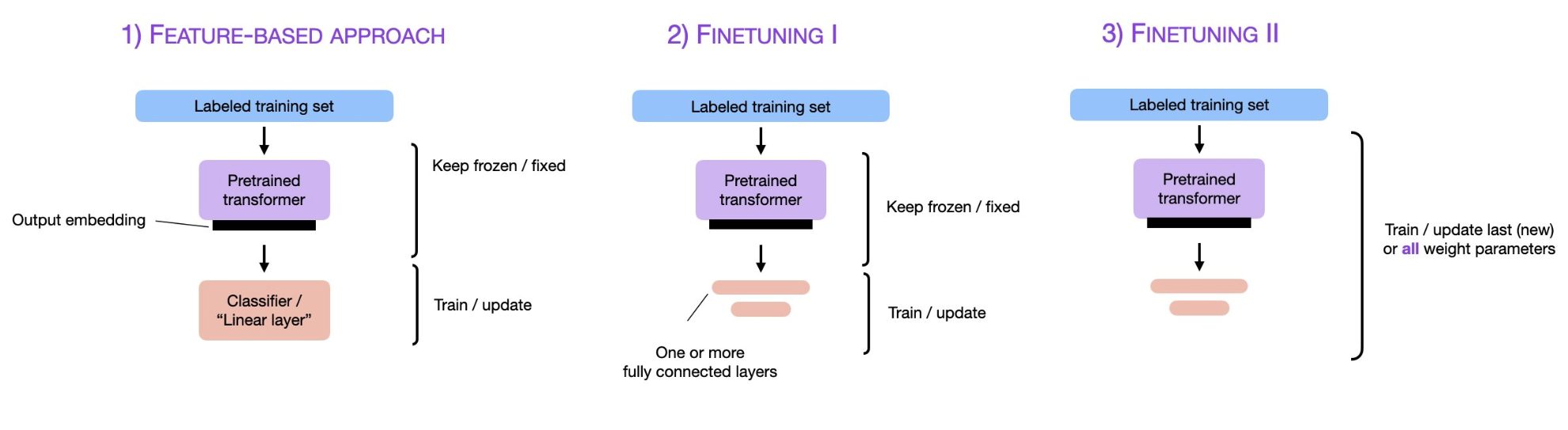
下图来自威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka的总结。