OpenAI内部通用大模型已经可以拿到国际数学奥利匹克竞赛金牌:AI推理能力已经接近人类顶级水平
1,627 阅读
几个小时前,OpenAI的研究人员披露,其一款内部实验性的大语言模型,在模拟的国际数学奥林匹克(International Math Olympiad,IMO)竞赛2025中取得了金牌水平的成绩。这是一个里程碑式的突破,因为IMO被认为是衡量创造性数学推理能力的巅峰,远超以往任何AI基准测试。这项成就并非通过专门针对数学能力对大模型进行定制的方法实现,而是源于通用人工智能研究的根本性突破,尤其是在处理难以验证的任务和长时间推理方面。

OpenAI大模型数学推理能力的进化:从解题到证明
国际数学奥林匹克(IMO)长期被视为 AI 推理能力的试金石。其挑战性在于:
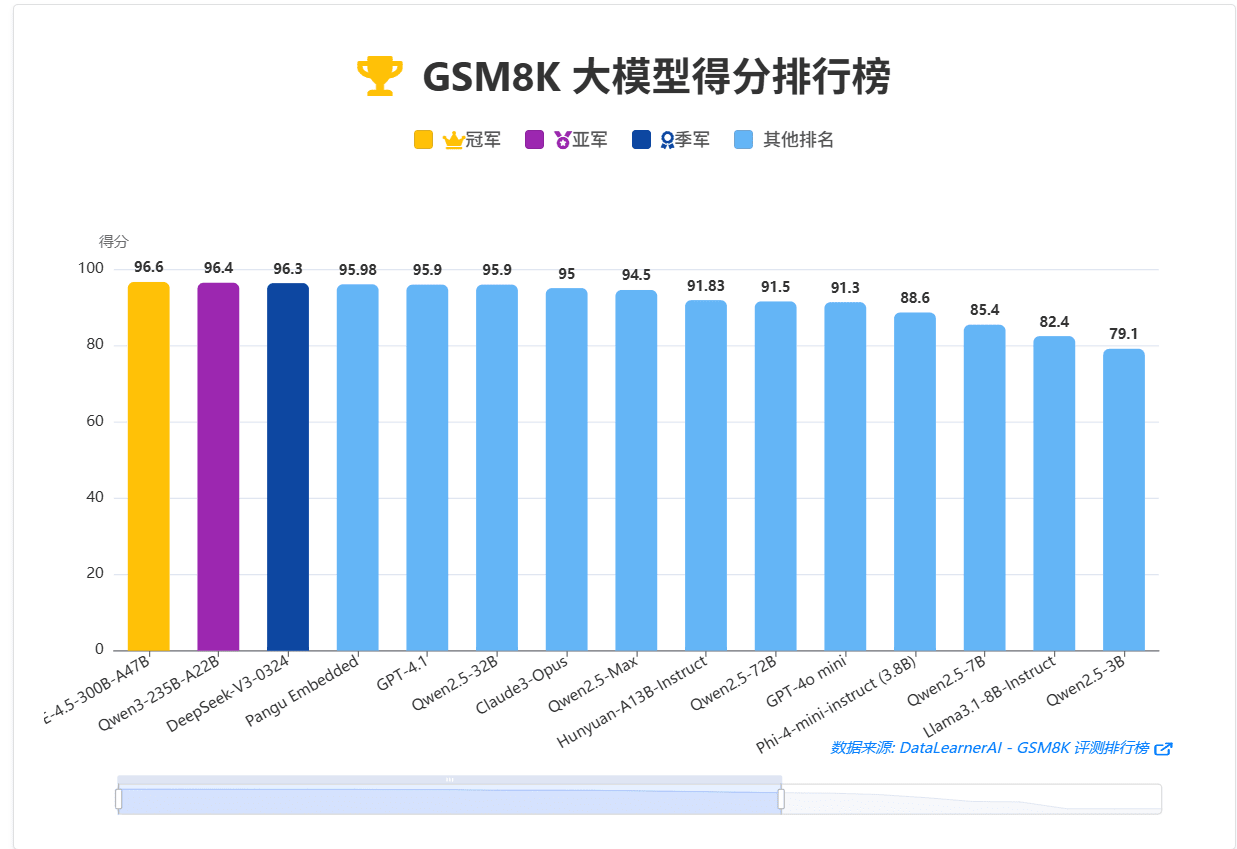
- 超长思维链:竞赛中,人类选手需在9小时内(两场各4.5小时)完成6道原创证明题,平均单题耗时约100分钟,远超当前大模型常见任务(如GSM8K约0.1分钟)。
- 严格约束:闭卷、纯自然语言推导、多页严谨证明——禁用计算工具与形式化验证器(如Lean)。这意味着模型不能使用外部工具。
- 模糊评估:答案并非单一数字,而是需要专家评审数小时才能鉴定的主观性证明。
OpenAI本次公布的实验性模型,正是在严格复现上述环境下进行的测试。最终,该模型在与人类选手相同的规则下解决了6道题中的5道(P1-P5),其证明过程由三位前IMO奖牌得主独立评审并达成共识,最终得分35/42,足以获得金牌(2024年金牌分数线为32分)。