大模型ARC-AGI-3评测基准:首个交互式推理基准
363 阅读
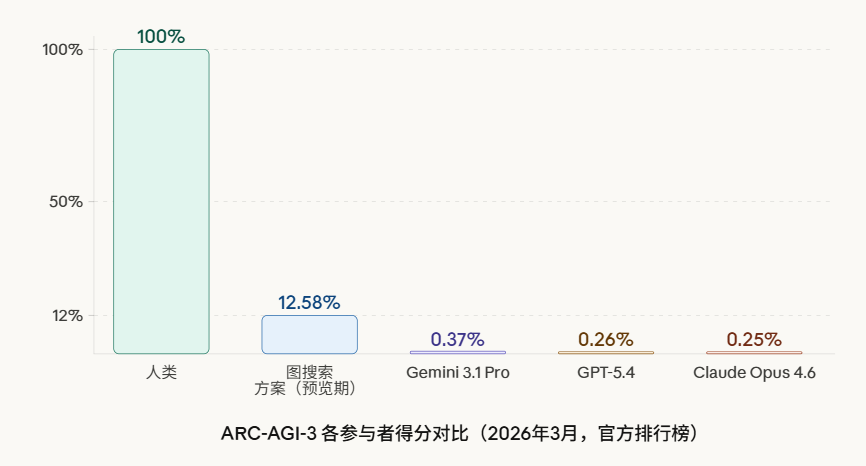
ARC-AIG-3最新完整的评测结果可以访问DataLearnerAI的ARC-AGI-3数据:https://www.datalearner.com/benchmarks/arc-agi-3
ARC-AGI 系列基准由 ARC Prize Foundation 维护,长期被主要 AI 实验室和学术研究者作为衡量 AI 推理能力的参照。
从形式上看,ARC-AGI 可以理解为一类“从示例中归纳规则”的任务集合。系统接收到若干组输入/输出示例,每个示例由小尺寸二维网格构成,网格中的每个单元为离散取值(通常表示颜色编号)。模型需要从这些示例中推断潜在的变换规则,并将该规则应用到新的输入上生成正确输出。
需要强调的是,这里的“图像”并非自然图片,而是抽象网格结构(可视为二维数组),任务不涉及现实语义理解,而是聚焦于结构归纳、模式组合与规则外推能力。
例如,一个典型任务可能如下:
输入:
0 0 0
0 2 0
0 0 0
输出:
0 0 0
0 3 0
0 0 0
在多个类似示例中,模型需要归纳出规则(如“将颜色 2 替换为颜色 3”),并将该规则应用到新的输入上。这类任务本质上属于从有限样本中进行程序归纳(program induction)。
2026年3月25日,该系列第三代版本 ARC-AGI-3 在旧金山 Y Combinator 正式发布,这是自2019年该系列初次推出以来,格式层面改动最大的一次迭代。