腾讯开源Hunyuan-A13B大模型:MoE架构,混合推理(支持直接回复和带推理过程后回复),原WizardLM团队打造,评测结果超Qwen2.5-72B,接近Qwen3-A22B,但参数量只有一半
1,067 阅读
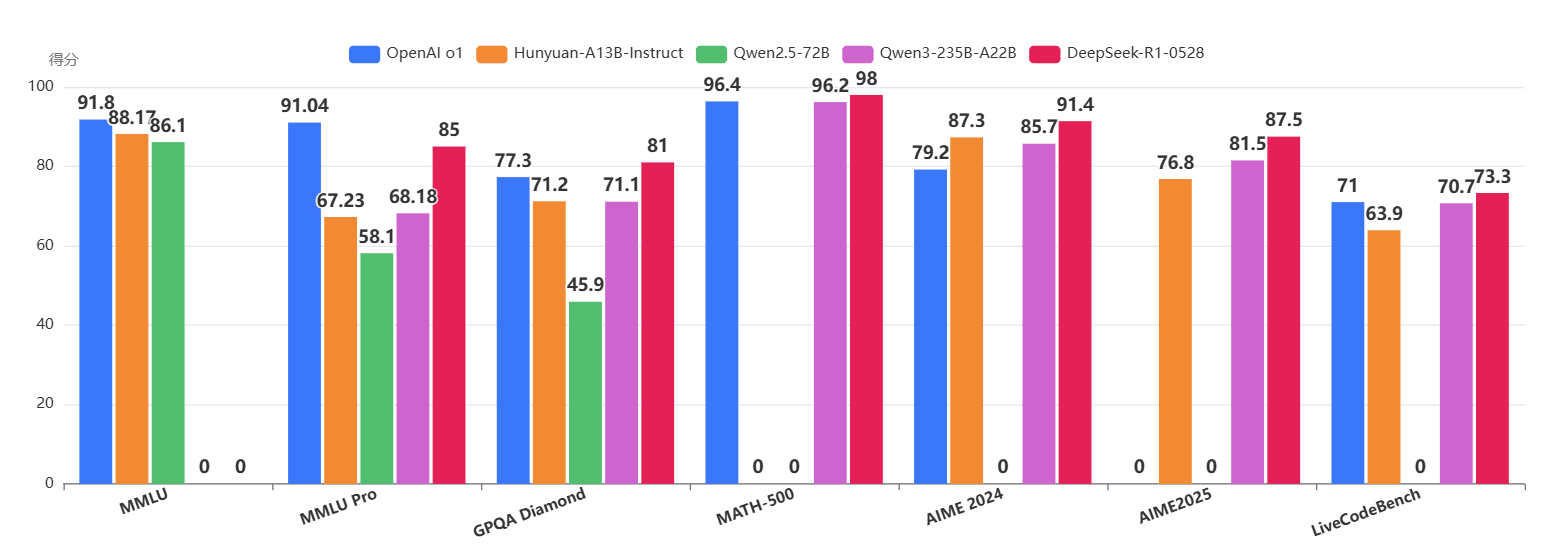
2025年6月27日,腾讯发布并开源了其混元大模型系列的新成员Hunyuan-A13B。该模型定位为一个基于细粒度专家混合(MoE)架构的大语言模型。其主要特点是高效率和可扩展性,旨在为开发者和研究人员,特别是在资源受限的环境中,提供高级推理和通用应用能力。Hunyuan-A13B是由原来的微软的WizardLM团队成员打造(二代WizardLM2在2024年开源打败了所有闭源模型,仅次于最新的GPT-4,似乎这件事在微软内部引起了很大的问题,不久后撤回了这个模型,团队成员也离职了,后面加入了腾讯)。

Hunyuan-A13B核心功能与技术特点
Hunyuan-A13B定位非常明确:一个为资源受限环境设计的高性能、高效率的通用大语言模型。它采用MoE(混合专家)架构,总参数800亿,每次推理激活130亿参数。模型最高支持256K的超长上下文推理。
这意味着,Hunyuan-A13B 在实际运行时,其计算开销和内存占用仅与一个13B规模的模型相当,但其知识储备和能力上限却是由800亿总参数决定的。
Hunyuan-A13B模型和Qwen3的混合推理架构类似,引入了一个非常人性化的设计——混合推理模式(Hybrid Inference)。用户可以根据需求,在“快思”(fast thinking)和“慢想”(slow thinking)之间灵活切换。
- 快思模式: 适用于常规问答、文本生成等需要快速响应的场景。