DataLearner AI 专注大模型评测、数据资源与实践教学的知识平台,持续更新可落地的 AI 能力图谱。
© 2026 DataLearner AI. DataLearner 持续整合行业数据与案例,为科研、企业与开发者提供可靠的大模型情报与实践指南。
法国人工智能初创企业MistralAI发布首个推理模型Magistral:纯RL训练,多语言能力出色,推理速度很快,Magistral Small (24B)版本免费开源,但面对Qwen3和DeepSeek稍显乏力 | DataLearnerAI
首页 / 博客列表 / 博客详情 Mistral AI今天发布了其首个专注于推理能力的系列模型——Magistral 。这次发布包含两个核心模型:旗舰模型Magistral Medium和已开源的 Magistral Small (24B)。最引人注目的亮点是,Mistral展示了其自研的强化学习(RL)pipeline能够从头开始,仅通过RL训练就将基础模型的推理能力提升到业界顶尖水平,而无需依赖任何其他预先存在的推理模型进行数据蒸馏。这套技术栈非常强大!
Mistral发布首个推理模型Magistral:纯RL训练带来性能飞跃,开源24B模型 Magistral模型简介
Mistral AI是法国的一家大模型初创企业,此前最著名的事情是业界最早开源MoE模型的企业,即Mixtral 8*22B,当时因为其直接开源,效果良好引起了大模型业界的追捧。但是,随着DeepSeek和Qwen系列模型的开源,以及Mistral转为商业目标为重心之后,它们在业界的影响力大大减少,不管是开源模型的节奏、数量还是质量都似乎不够吸引人了。
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
MistralAI当前主力模型分为三个不同版本,即Mistral Large、Mistral Medium和Mistral Small,其中Small版本是240亿参数版本的模型,一直开源,最新版本是3.1,而Medium是不开源的企业版本,因为其良好的多语言能力、较好的推理速度,以及还可以的效果,同时可能是欧洲大模型独苗,在OP市场上还是有点竞争力(纯粹个人观点,不喜勿喷),但可能没有此前大家那么期待和关注。
本次开源的Magistral是Mistral AI在增强大型语言模型(LLM)推理能力方面迈出的关键一步。它不是一个全新的基础模型,而是基于Mistral现有模型通过专门的推理训练方法优化而来的,得到的推理大模型。有2个版本:
Magistral Medium : 基于Mistral Medium 3模型,仅通过纯粹的强化学习(RL)进行训练,专注于提升数学和代码等复杂任务的推理能力。Magistral Small : 基于Mistral Small 3(一个24B模型),采用了从Magistral Medium蒸馏的SFT(监督微调)和后续RL相结合的训练方式,最终以Apache 2.0许可证开源 。 Mistral在论文中强调,他们的工作是“从零开始”(ground up),完全依赖自家的模型和基础设施,主要贡献包括:
纯RL的强大能力 :证明了仅用RL就能在没有外部推理数据的情况下,将模型性能(如AIME-24测试)提升近50%。可扩展的RL架构 :详细介绍了一个异步、高效的在线RL训练系统,能够平衡效率和策略的“在线性”(on-policyness)。简单有效的多语言策略 :通过简单的奖励机制,让模型的思考过程和最终答案都能使用用户的语言。对RL研究的贡献 :分享了许多实验洞见,包括一些成功和不成功的尝试,为社区提供了宝贵的经验。
Magistral性能评测:推理能力大幅提升 相比较基座模型,Magistral的性能提升明显,各项评测指标提升幅度都较大。以Magistral Medium为例,和它的基础模型 Mistral Medium 3相比较:
AIME'24 (pass@1): 从 26.8% 飙升至 73.6%。正确率提升了近 175%!这表明 RL 极大地增强了模型解决复杂数学问题的能力。
AIME'25 (pass@1): 从 21.2% 提升至 64.9%,提升超过 200%。
LiveCodeBench (v5): 从 29.1% 提升至 59.4%,提升超过 100%,在编程能力上同样效果显著。
GPQA (STEM): 从 59.6% 提升至 70.8%,在科学推理上也有显著进步。
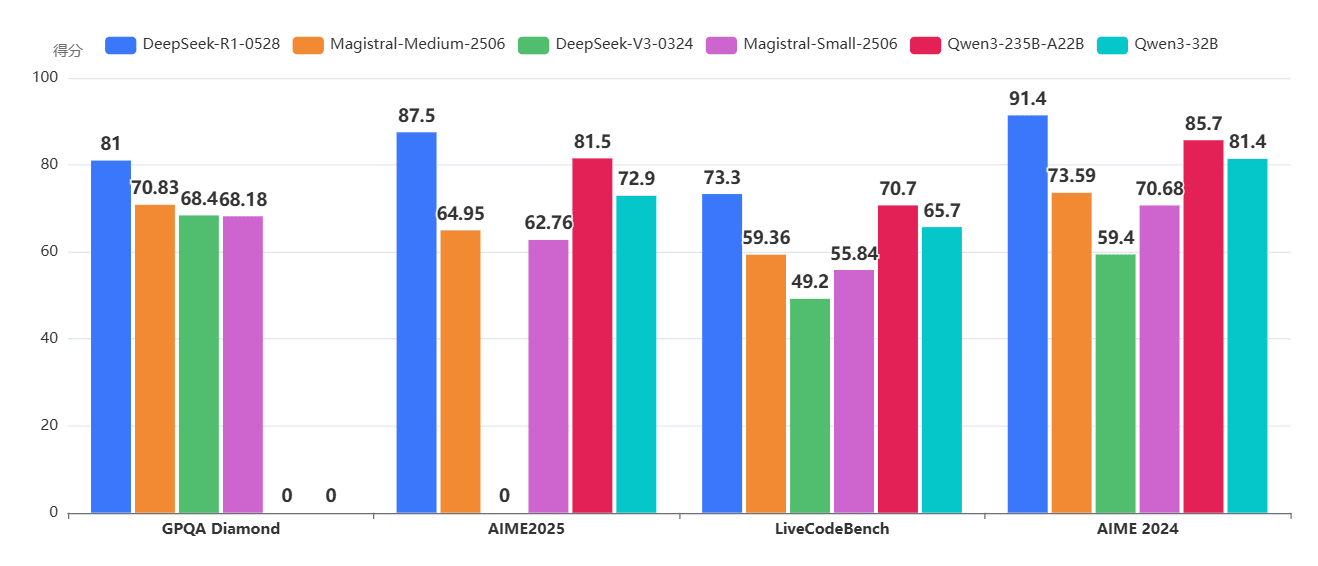
但是,这个提升的结果与业界最好的模型相比,似乎不够出色,特别是与国内开源的Qwen和DeepSeek相比,似乎不太优秀:
数据来源:https://www.datalearner.com/ai-models/ai-benchmarks-tests/compare-result?benchmarkInputString=32,42,40,37&modelInputString=586,585,576,567,543,566
从DataLearnerAI收集的数据来看,除了DeepSeekV3这个非推理模型外,Magistral两个版本模型都不如其它模型,虽然说数据没有那么差,但的确还是Qwen和DeepSeek太靓眼了。
Magistral核心技术解析:自研RL框架与GRPO算法 Magistral主要依赖Mistral自研的一套高效、可扩展的在线RL训练框架。这个框架协调了三种工作角色:Trainer (更新模型权重)、Generator (生成推理内容)和Verifier (评估并给予奖励)。
在算法层面,Mistral选择了GRPO (Group Relative Policy Optimization) ,并做出了几项关键优化:
移除了KL散度惩罚 :他们发现,在GRPO中,即使没有KL散度来约束模型偏离初始版本,策略本身也会发生显著变化。为了节省计算资源,他们干脆去掉了这一项。优势归一化(Advantage Normalization) :在每个minibatch内对优势进行归一化,以稳定训练。放宽信任区域上界(Clip-Higher) :允许模型探索那些概率较低但可能非常有价值的推理路径,以防止策略过早“熵坍塌”(变得过于确定和单一)。奖励塑造(Reward Shaping) :奖励不仅仅是“答案对不对”,而是一个综合性的评分,包括:
格式正确性 :是否遵循<think>标签、\boxed{}等格式要求。答案正确性 :数学和代码答案是否通过验证。长度惩罚 :对过长的输出进行轻微惩罚。语言一致性 :奖励思考过程和答案使用相同语言。
这个精巧的框架和算法设计,是Magistral性能飞跃的基石。
对于开源的24B模型Magistral Small,Mistral采用了“SFT+RL”的黄金组合路线:
SFT阶段 :使用Magistral Medium生成的优质推理轨迹,对Mistral Small 3进行监督微调(SFT)。RL阶段 :在SFT模型的基础上,再进行强化学习。 这一发现与之前一些研究(如DeepSeek)认为“小模型纯靠RL效果不佳”的观点不同,Mistral证明了即使在小模型上,强大的RL技术也能带来超越蒸馏的显著增益 。
意外之喜:RL训练带来的“免费午餐” 最令人惊喜的发现是,针对文本推理的RL训练不仅没有损害模型原有的其他能力,反而还带来了提升 ,堪称“免费的午餐”。
多模态能力 :尽管RL训练只用了纯文本数据,但Magistral模型在MMMU和MathVista等多模态基准上的表现反而更好了。这表明模型学会的“深度思考”模式可以泛化到处理图像和文本结合的问题。
工具调用与指令遵循 :同样地,模型在函数调用(Function Calling)和指令遵循(Instruction Following)等能力上也保持稳定,甚至有小幅提升。
这意味着,Magistral模型可以直接集成到现有的工具使用和Agent工作流中,无需担心能力退化。
Magistral模型的多语言能力 通过在训练数据中加入10%的多语言问题,并设置“语言一致性奖励”,Magistral模型学会了用用户的语言进行思考和回答。一如既往,Mistral的模型在支持多语言的方面还是很优秀的,以AIME2024测试为例,其它语种相对于英文,下降不明显:
虽然在非英语语言上性能有轻微下降,但这证明了该方法是有效的,并且模型的整个推理链(<think>标签内的内容)都是用目标语言完成的,非常地道。
Magistral的开源情况和总结 Magistral Small (24B)模型已经根据Apache 2.0许可证在Hugging Face上开源,你可以直接下载使用。
重磅!阿里开源325亿参数规模的推理大模型QwQ-32B:性能接近DeepSeek R1满血版,参数更低,免费商用授权!