大规模中文开源数据集发布!2TB、几十亿条可商用的中文数据集书生·万卷 1.0开源~中文大模型能力可能要更上一层楼了!
5,135 阅读
随着近年来GPT-3、ChatGPT等大模型的兴起,高质量的数据集在模型训练中扮演着越来越重要的角色。但是当前领先的预训练模型使用的数据集细节往往不公开,开源数据的匮乏制约着研究社区的进一步发展。特别是大规模中文数据集十分缺乏,对中文大模型以及业界模型的中文支持都有很大的影响。此次,上海人工智能实验室发布的这个书生·万卷 1.0数据集包含了丰富的中文,对于大模型的中文能力提升十分有价值。

书生·万卷 1.0数据集概览
书生·万卷 1.0数据集整合了中文和英文数据,内容涵盖文本、图像文本和视频三种模态,数据总量超过2TB。文本数据中包含不同领域的6亿份文档;图像文本数据经处理后形成了超过2200万个文档;视频数据有1000多个文件。
在数据集的构建中,研究团队通过算法处理和人工审核相结合的方式,确保了数据的安全性、高质量以及价值取向。所有数据均采用统一的JSON格式组织,并提供了数据集下载工具及相关文档。
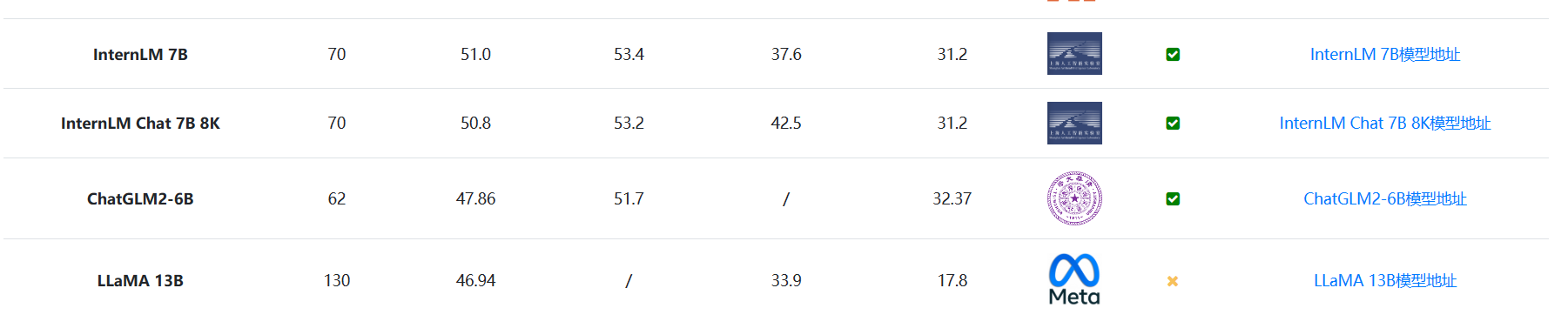
这个开源的大规模多语言多模态数据集已被用于InternLM模型的训练,相比同规模模型,InternLM在多维度评测中展现出明显优势。WanJuan的发布填补了公开源数据的空白,有助于自然语言处理、计算机视觉等领域的技术进步,特别是需要多模态理解生成的任务。
InternLM模型在各项评测中也十分优秀,看样子这份数据集功不可没!