突破英特尔CPU+英伟达GPU的大模型训练硬件组合:苹果与AMD都有新进展!
2,603 阅读
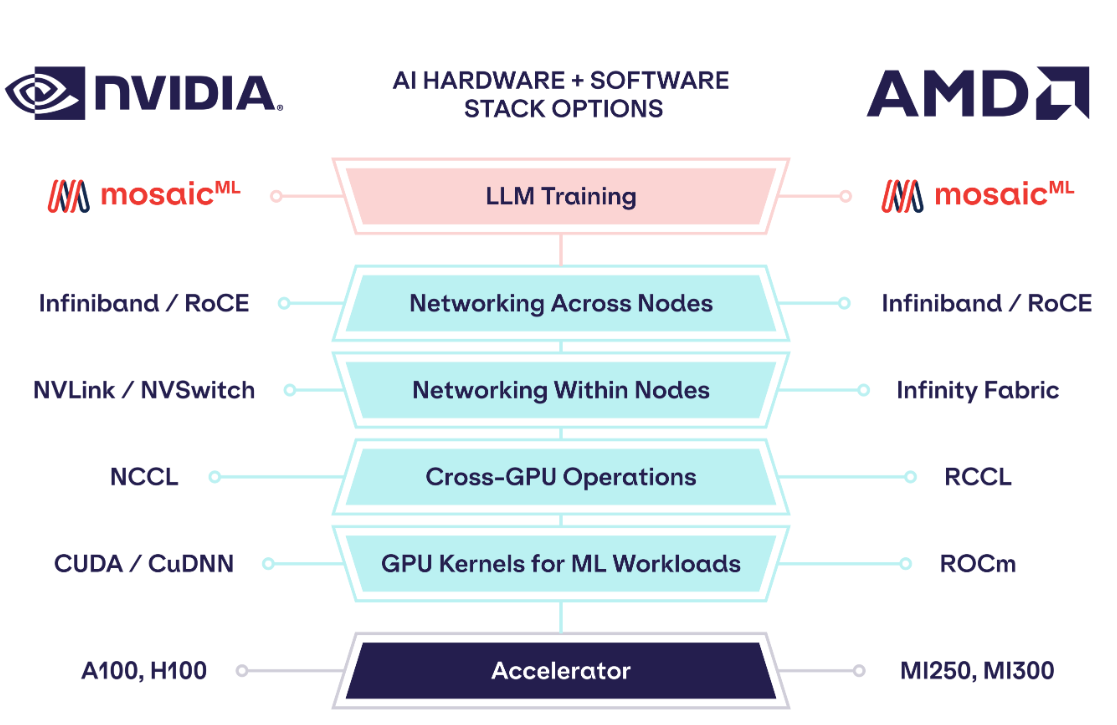
大语言模型的训练和微调的硬件资源要求很高。现行主流的大模型训练硬件一般采用英特尔的CPU+英伟达的GPU进行。主要原因在于二者提供了符合大模型训练所需的计算架构和底层的加速库。但是,最近苹果M2 Ultra和AMD的显卡进展让我们看到了一些新的希望。
本文主要介绍一下苹果芯片和基于AMD软硬件系统的大模型训练体系做简单的介绍。因为二者最新的硬件和生态建设都让我们有一种新的性价比选择。尽管除了硬件外还需要考虑加速库和开源库的选择,但是开源的速度让我们看到这些新选择完全没问题。
基于因特尔CPU+英伟达GPU的大模型训练基础架构
当前主流的大模型架构都是基于transformer的架构,属于一种深度学习架构的模型。使用GPU训练深度学习架构的大模型主要优势在于:
-
高性能计算:深度学习中的大部分计算都是浮点计算,包括矩阵乘法和激活函数的计算。GPU的设计目标是为了高性能图形渲染,因此它们在浮点计算方面表现出色。
-
并行计算能力:GPU的另一个主要优势是其高度并行的计算架构。深度学习模型通常需要执行大量的矩阵乘法和向量运算,这些操作可以以高度并行的方式进行。GPU具有大量的处理单元,能够同时执行多个计算任务,从而提高了训练深度学习模型的效率。
-
高内存带宽:GPU提供高达几百GB/s的内存带宽,满足深度学习模型对数据的大容量访问需求。
然而,大模型的训练只有GPU是不够的。GPU主要负责并行计算和深度学习模型的训练,而CPU则负责处理数据的预处理、后处理以及管理整个训练过程的任务。GPU和CPU之间的协同工作可以实现高效的大规模模型训练。
那么,为什么当前大多数大模型训练采用因特尔的CPU加英伟达的GPU作为计算基础设施呢?