DataLearner AI 专注大模型评测、数据资源与实践教学的知识平台,持续更新可落地的 AI 能力图谱。
© 2026 DataLearner AI. DataLearner 持续整合行业数据与案例,为科研、企业与开发者提供可靠的大模型情报与实践指南。
如何用7.7亿参数的蒸馏模型超过5400亿的大语言模型——Google提出新的模型蒸馏方法:逐步蒸馏(Distilling step-by-step)详解 | DataLearnerAI
首页 / 博客列表 / 博客详情 1750亿参数规模的模型需要350G的GPU显存才能做推理,显然,这样大规模的模型在实际应用中压力会很高。对于大多数产品或者团队来说,这都是一个难以负担的成本。
为此,华盛顿大学研究人员与Google的研究人员一起在5月3日公布了一个新的方法,即逐步蒸馏(Distilling step-by-step)法,这个方法最大的特点有2个:一是需要更少的数据来做模型的蒸馏(根据论文描述,平均只需要之前方法的一半数据,最好的情况只需要15%的数据就可以达到类似的效果);二是可以获得更小规模的模型(最多可以比原来模型规模小2000倍!即可获得大模型差不多的效果)。
需要注意的是,逐步蒸馏(Distilling step-by-step)方法可以应用在所有类型的语言模型中,没有限制!这个方法应该是非常有价值的,对于未来我们做模型小型化有很大的帮助,也在推特上吸引了很多的讨论。本文将详细解释一下这个方法的核心思想。
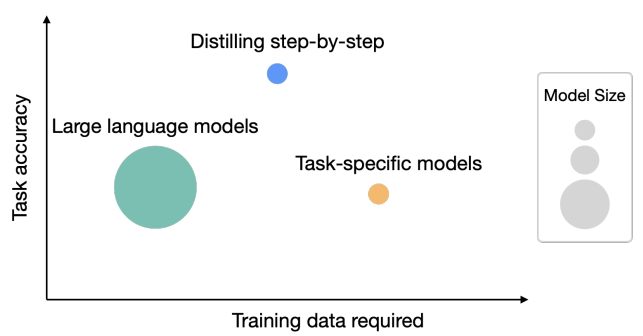
下图是一个简单的示意图,可以看到逐步蒸馏法的优势:
本文将从如下几个方面介绍这个方法。
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
当前Finetuning与Distillation方法的缺点 如前所述,大模型直接应用的成本很高。因此,研究人员提出了使用finetuning与distillation来降低模型的部署应用成本。
Finetuning方法一般是针对下游任务,使用与下游任务相关的标注数据来更新模型的一部分参数,降低模型在特定任务上应用的成本。而Distillation是一种用于训练小型模型的技术,该技术从已经训练好的大型模型中提取知识,并将其转移给小型模型。模型蒸馏的目标是生成一个小型模型,其性能接近于大型模型,同时具有更高的效率和更小的内存占用。
不幸的是,这两种方法也有一定的成本:为了达到与LLMs相当的性能,Finetuning需要昂贵的人工标签,而蒸馏需要大量的未标记数据,这可能难以获取。
逐步蒸馏法(Distilling step-by-step)的特点 这篇论文提出的逐步蒸馏法(Distilling step-by-step)最大的亮点如下:
首先,与微调和蒸馏相比,逐步蒸馏法得到的模型平均下来只需要一半的数据就能实现更好的性能(最多可减少85%)。
其次,这样的模型使用更小的规模(最多小2000倍)就能胜过原始的大语言模型,极大地降低了模型部署所需的计算成本。
论文只使用一个7.7亿规模的T5模型就超越了使用5400亿参数LLMs的性能;如果使用现有的微调方法,该更小的模型仅使用标记数据集的80%就能达到预期,否则需要更多的数据。
当只有未标记数据时,该模型仍然能够与LLMs相当或更好地表现。我们使用一个110亿参数的T5模型就超越了使用5400亿参数的PaLM的性能。论文还证明了,当一个小型模型表现不如LLMs时,Distilling step-by-step相比标准的蒸馏方法更有效地利用额外的未标记数据以达到LLMs的性能。
逐步蒸馏法(Distilling step-by-step)的原理
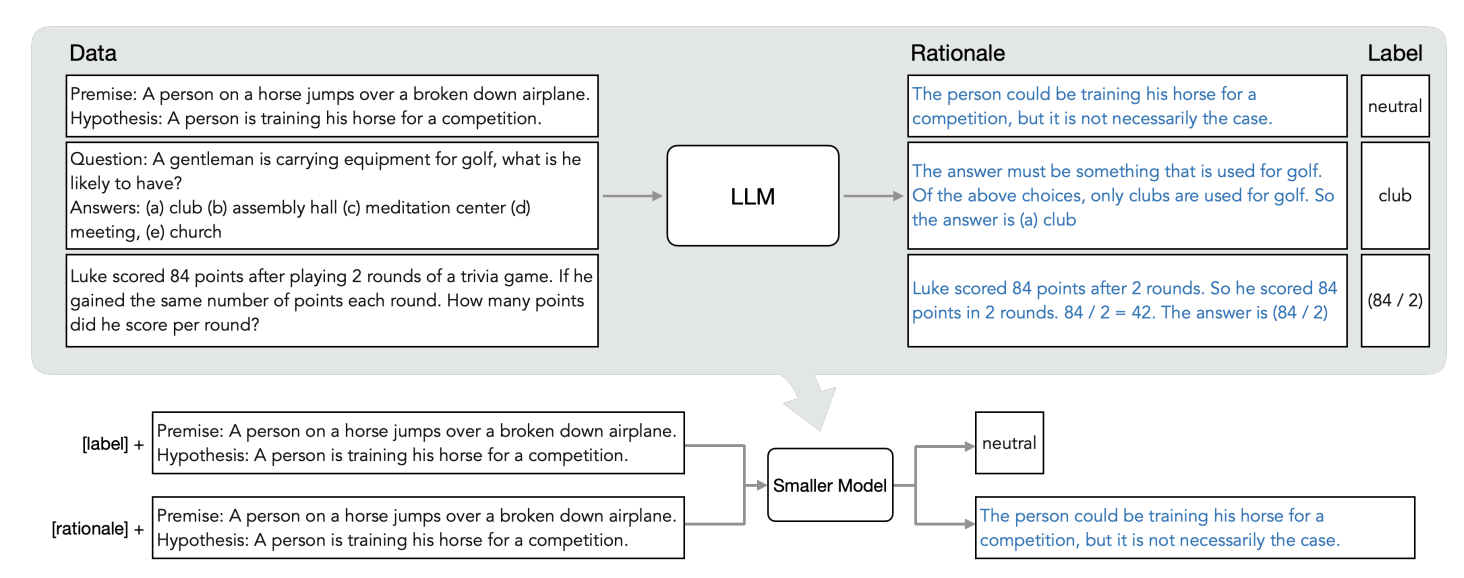
Distilling step-by-step总体框架如图所示。含两个简单的步骤:首先,给定一个LLM和一个未标记的数据集,该方法首先使用思维链方法来从LLM种抽取一种名字叫合理性(Rationales)的东西。然后利用生成的合理性在一个多任务学习框架种训练特定任务的小模型。
合理性(Rationales)是最近一些研究中发现的关于大语言模型的一个性质:即大语言模型能够生成支持其预测的解释性语言表述,这种表述被称为合理性(Rationales)。不过之前的研究主要关注的是如何解释或者理解合理性(Rationales)产生的原理和机制。而本文则是希望利用思维链技术来从LLMs中抽取合理性。如下图所示:
大致原理就是,给定一个大模型和一个无标记的数据。作者首先设计一种提示模板,这个提示模板主要是阐述这样的任务该如何解决。这个提示模板包含3个部分,一个是输入,一个是输出标签,另一个是由用户给出的为什么这个输入可以得到这个标签。
接下来就是如何将上面得到的合理性(Rationales)用于下游的任务中。方法很多,作者将学习合理性(Rationales)作为一个多任务学习问题。让接下来的模型不仅需要预测输出的标签,还需要生成相关的合理性(Rationales)。作者并据此提出了一个合理性生成损失函数作为模型学习的目标,引导模型预测最终的标签,这就是逐步蒸馏法(Distilling step-by-step)的核心。
从上面的内容看,这个方法最主要的就是先通过人工标注或者大模型来生成合理性(Rationales)相关的数据集,并在后续的学习中,将模型预测标签和生成合理性都当作后续模型训练的目标来引导模型更好地预测结果。
逐步蒸馏法(Distilling step-by-step)的实验结果
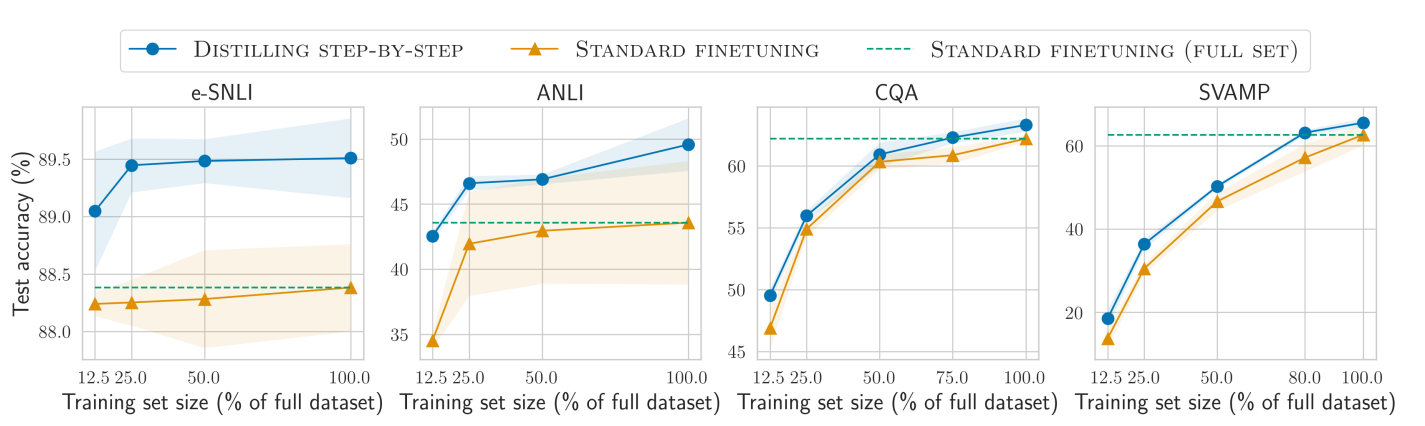
逐步蒸馏法(Distilling step-by-step)与微调方法使用数据集多少对比 首先是作者对比了标准的微调方法。如下图所示,绿色圆点是逐步蒸馏法(Distilling step-by-step),黄色三角形是微调方法,虚线是全量数据微调方法。
每个图是一类任务,每一个图的横坐标表示逐步蒸馏法(Distilling step-by-step)与微调方法分别使用了百分之多少的有标注数据。对比基准就是虚线的全量数据微调结果。可以看到,最左侧是使用12.5%的数据集来对比逐步蒸馏法(Distilling step-by-step)和微调方法,显然逐步蒸馏法(Distilling step-by-step)比微调效果更好。随着数据集增加,逐步蒸馏法(Distilling step-by-step)效果也在迅速增加。在前两类任务中,25%的数据集就足够让逐步蒸馏法(Distilling step-by-step)超过全量数据微调了。而后两种任务中,75%的数据集下,逐步蒸馏法(Distilling step-by-step)与全量数据微调水平差不多。
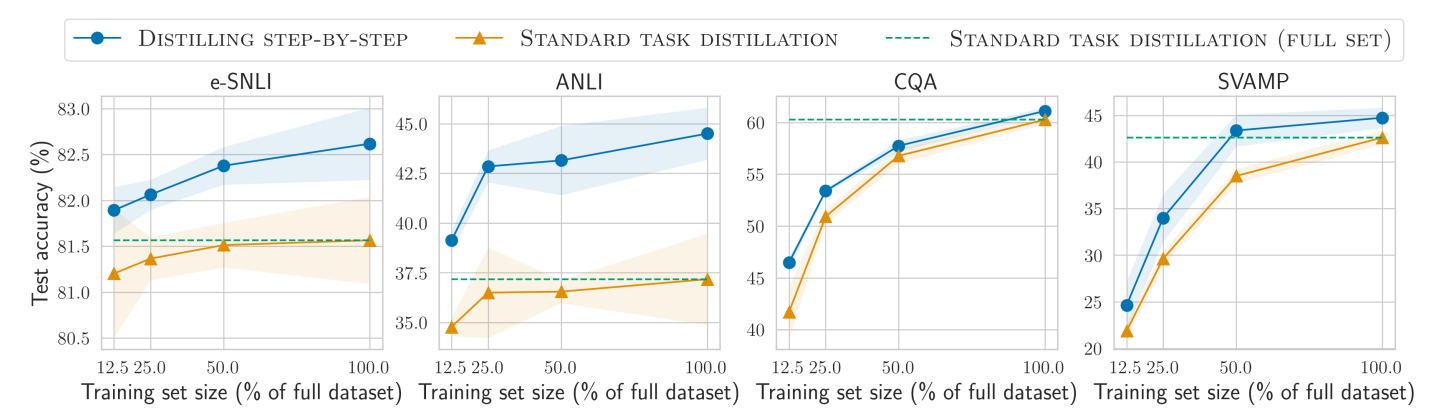
逐步蒸馏法(Distilling step-by-step)与正常蒸馏方法对比
显然,逐步蒸馏法(Distilling step-by-step)效果也是很好。除了CQA任务外,其它任务逐步蒸馏法(Distilling step-by-step)都有明显的优势,只需要一半不到的数据即可。
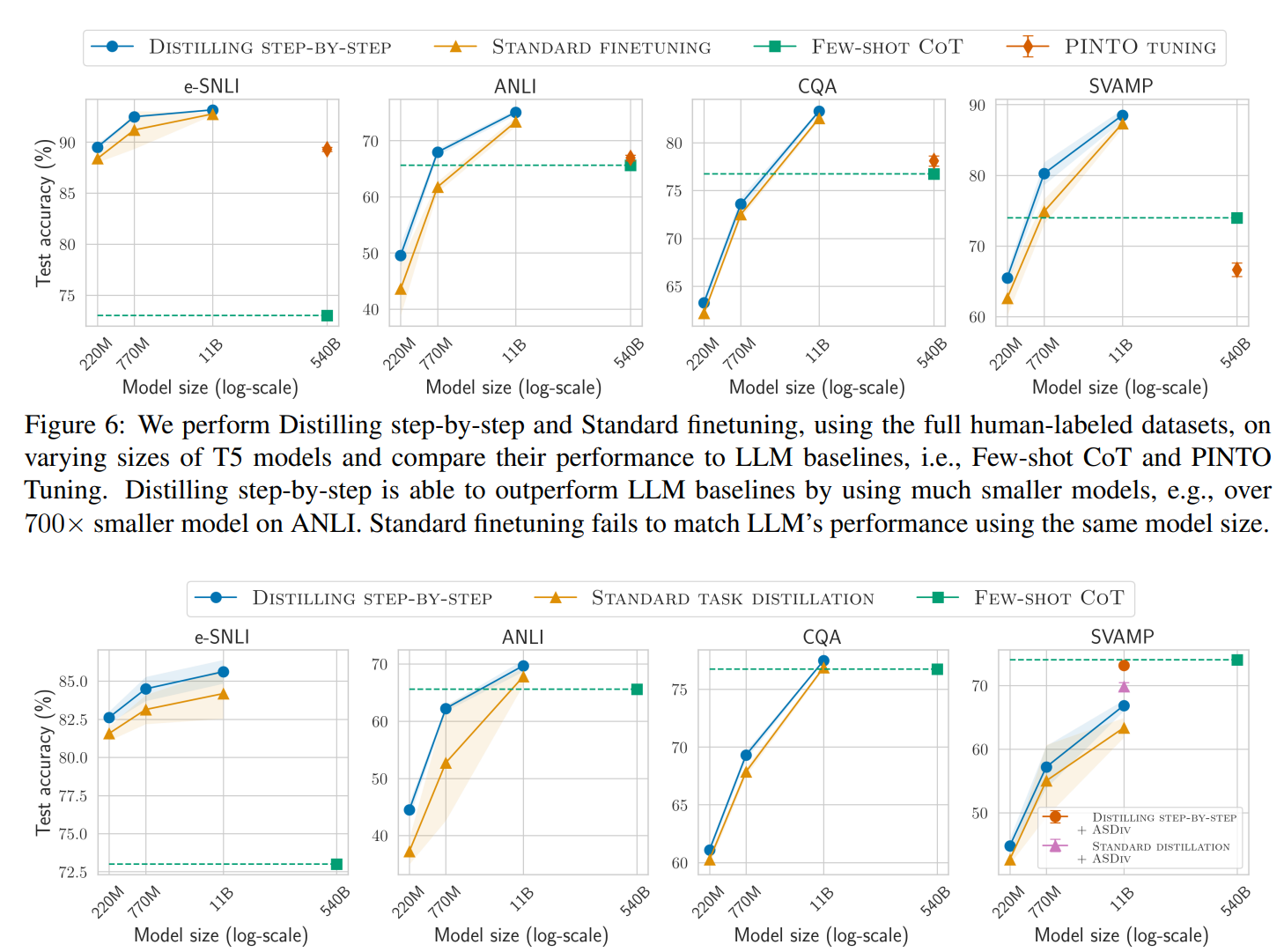
逐步蒸馏法(Distilling step-by-step)使用的模型参数对比
图中展示的是与微调方法和蒸馏方法的对比。其中虚线都是5400亿的基准大模型,横坐标表示分别用2.2亿、7.7亿、110亿等规模的小模型来与基准模型对比。可以看到,4个任务中,逐步蒸馏法(Distilling step-by-step)与微调相比,7.7亿参数规模就可以超过5400亿参数规模的大模型了(CQA任务需要110亿参数)。而与蒸馏方法相比,则优势缩小了。
逐步蒸馏法(Distilling step-by-step)总结 从前面分析来看,逐步蒸馏法(Distilling step-by-step)是一个非常巧妙的模型蒸馏方法。其实也是和思维链类似。把大语言模型在生成任务上的优势引入到模型蒸馏中来。合理性显然是模型生成正确答案的一个非常重要的基础。如果能把大模型生成合理性的逻辑让小模型学到,可能就不需要更多规模的数据和参数就能让模型有更好的能力。从这个层面看,如果语言模型可以生成比较好的合理性(Rationales),可能就能有比较好的性能了!