微软开源DeepSpeed Chat——一个端到端的RLHF的pipeline,可以用来训练类ChatGPT模型。
RLHF全称Reinforcement Learning from Human Feedback,是随着ChatGPT火爆之后而被大家所关注的技术。昨天,微软开源了业界第一个RLHF的pipeline框架,可以用来训练类似ChatGPT的模型。
RLHF是什么?为什么RLHF很重要
强化学习(RL)是一种机器学习类型,允许代理通过试错学习如何在环境中行为。代理被赋予一个目标和奖励函数,并且必须学习采取最大化其预期奖励的行动。
RL在学习复杂任务方面非常有效,但也可能非常具有挑战性。其中一个挑战是很难设计一个准确反映代理目标的奖励函数。如果奖励函数不准确,代理可能会学会以不理想的方式行为。
从人类反馈中进行强化学习(RLHF)是一种可以解决这个问题的技术。在RLHF中,代理被赋予一个初始非常简单的奖励函数。然后代理与环境进行交互,并从人类接收反馈。人类反馈被用于更新奖励函数,这进而有助于代理学会更理想的行为方式。
已经证明,RLHF可以有效地学习各种任务,包括玩游戏、控制机器人和编写文本。这是一种有前途的技术,可以用于训练代理在复杂和具有挑战性的环境中的行为方式。
为什么RLHF的开源实践很少
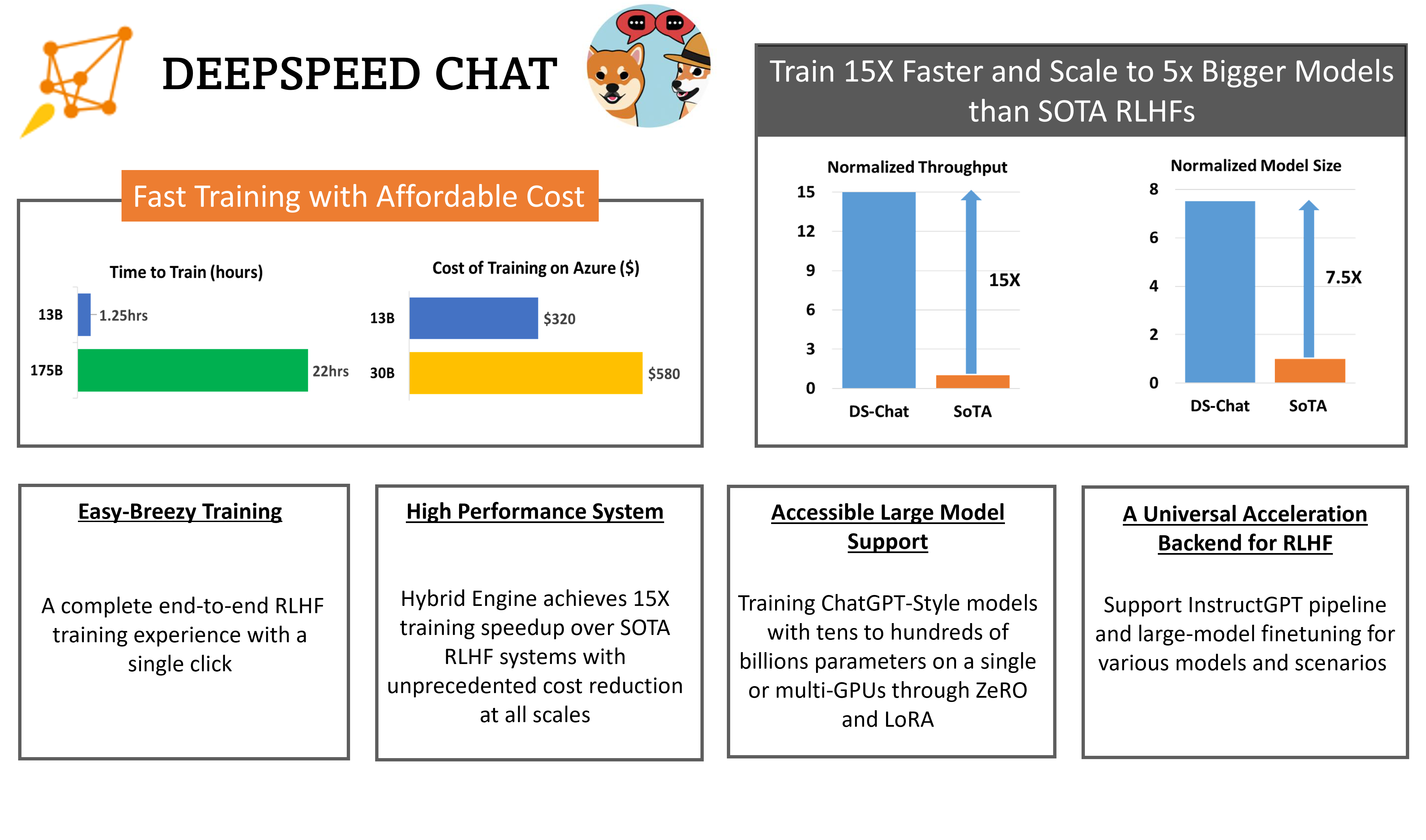
尽管AI开源社区正在进行多项努力,以使类ChatGPT模型更易于访问(例如ChatLLaMa、Alpaca、Vicuna、Databricks-Dolly等)。但是仍然缺乏一种能够让AI社区轻松访问并训练强大的类ChatGPT模型的端到端RLHF管道。例如,使用现有系统训练一个仅有67亿参数的类ChatGPT模型通常需要昂贵的多GPU设置,超出了许多数据科学家的能力范围。即使拥有这样的计算资源,训练效率通常也不到这些机器能力的5%(稍后将说明)。最后,现有的解决方案仅仅无法支持便捷、快速和实惠地训练具有数百亿参数的最先进的类ChatGPT模型,即使拥有多GPU集群的访问权限。
这些限制源于InstructGPT使用的复杂RLHF训练管道在现有DL系统中得不到很好的支持,这些系统是为更传统的预训练和微调管道进行优化的。
微软开源的DeepSpeed-Chat框架介绍
为了使类ChatGPT模型更广泛可用和RLHF训练更易于访问,微软团队发布了DeepSpeed-Chat,提供了一个端到端的RLHF管道来训练类ChatGPT模型。它具有以下特点:
