能否用85000美元从头开始训练一个打败ChatGPT的模型,并在浏览器中运行?
1,638 阅读
尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。
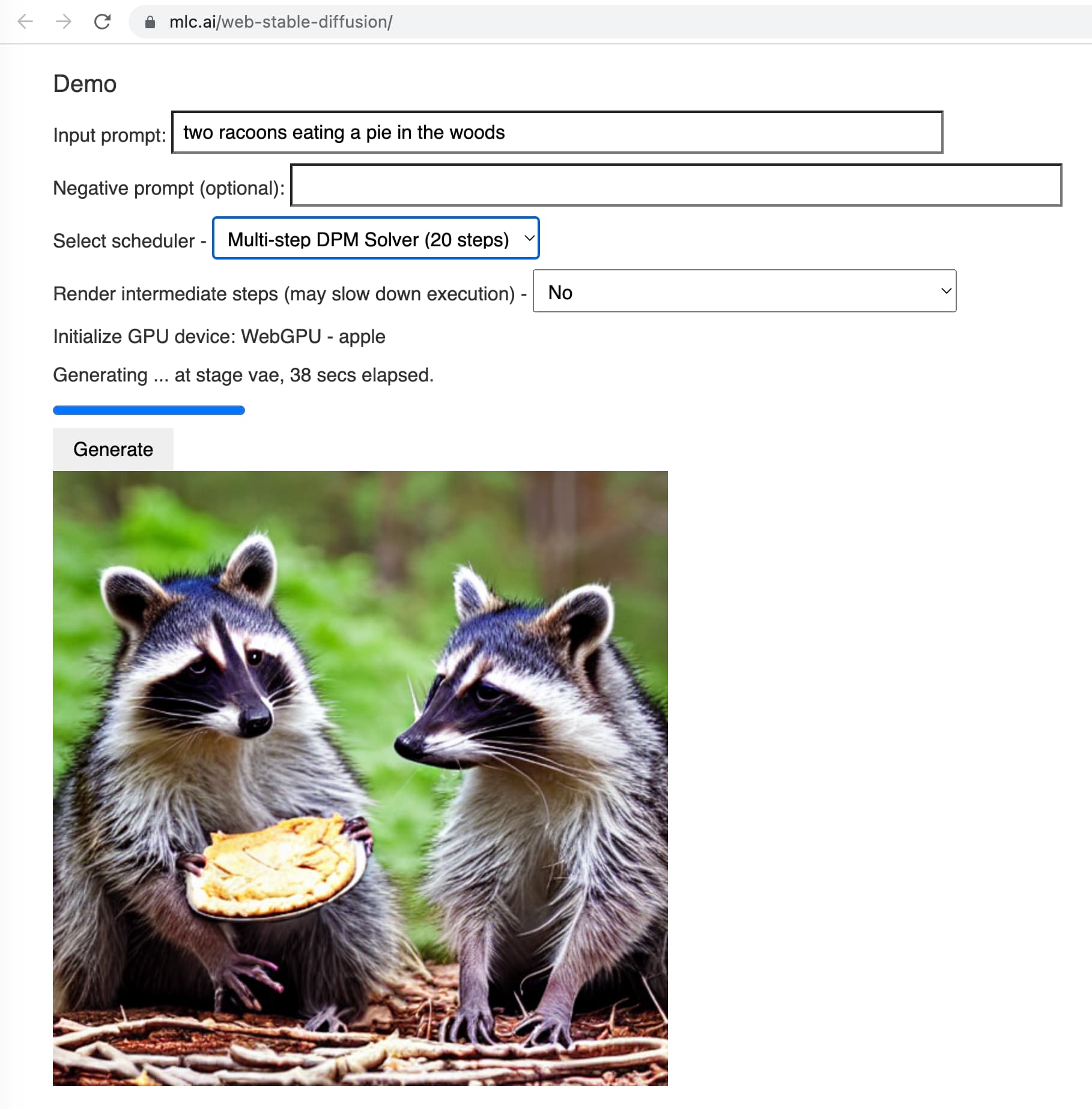
Django的共同创始人Simon Wilison最近发表了一篇博客,介绍最近的模型进展使得大家可以用8.5万美元从头训练一个类似ChatGPT的模型。其实最主要的办法就是你训练一个70亿参数规模的LLaMA(MetaAI开源的),然后用斯坦福大学的Alpaca的指令微调方法做微调(成本不到100美元)。这两个加在一起,效果与ChatGPT比较还是不错的。而且这两个模型都是开源的,并且有详细的细节介绍。
注意,本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!
本文根据Simon Willison的博客介绍了如何得出这样一个8.5万美元成本的ChatGPT模型:
一、大语言模型的训练成本
构建具有类似GPT-3能力的大型语言模型需要数百万美元的费用,这归因于运行需要昂贵GPU服务器的高昂成本。无论是租用还是购买这些设备,都需要支付巨额能源成本。
一个例子是BLOOM大型语言模型(模型卡地址:https://www.datalearner.com/ai/pretrained-models/bloom ),在法国得到了法国政府的支持,其费用被估计为200万-500万美元,花费了近4个月的时间进行训练,并因大部分电力来自核反应堆而夸耀其低碳足迹!