深度学习模型训练将训练批次(batch)设置为2的指数是否有实际价值?
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。
简介
对于整数参数来说,固定在2的幂上是我们经常看到的一种软件工程习惯。例如,你可能听过这样的建议:为你的批次大小选择2的幂。Andrew Ng在他的一门deeplearning.ai课程中报告了64、128、256和512的典型批量大小,NVIDIA建议Tensor Cores选择8的倍数,甚至Goodfellow, Bengio & Courville在他们的《深度学习》一书中指出
一些种类的硬件通过特定尺寸的阵列实现更好的运行时间。特别是在使用GPU的时候,一般来说,2个批次可以提供更好的运行时间。
普通图像分类测试
我们先在一个大约有3000张图片的数据集上进行普通图片分类训练。训练是使用带有NVIDIA P100(不包含Tensor Cores)的Kaggle笔记本进行的。
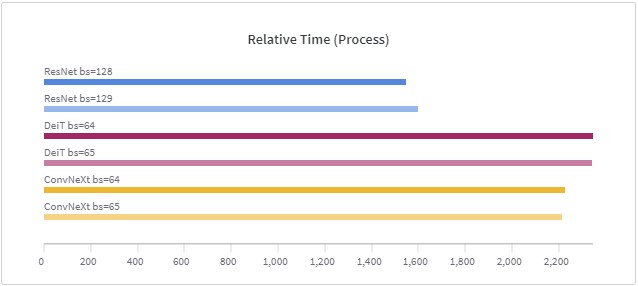
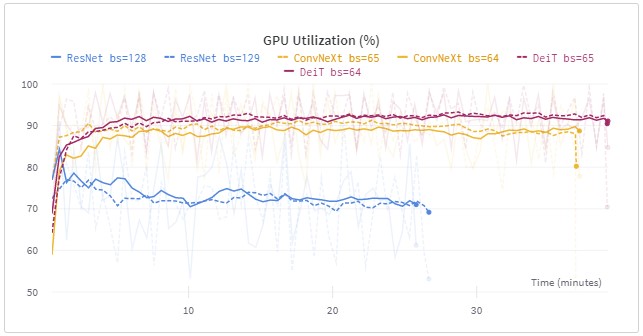
微调包括一个现代的ConvNeXt、一个普通的ResNet和一个DeiT transformer模型,批次大小不同。 ResNet(80次epoch,批次大小为128和129):26分钟 DeiT(40次epoch,批次大小为64和65):39分钟 ConvNeXt(40个epoch,批次大小为64和65):37分钟 在下面的图中,你会看到批处理规模的颜色相似。你还会看到,不同批处理量的训练时间几乎是相同的。