C/C++源代码是如何被最终执行的?
C/C++的源程序文件都是程序员按照相关语法和规则编写的。但是这样的程序文件并不能直接被硬件识别和执行。本文将简要描述C/C++的源代码是如何经过转化并最终转变成可以被硬件识别执行的二进制文件的。
C语言是一种结构化的编程语言。与Java、Python编程语言相比,C语言更加接近汇编语言。但是C语言依然算是可以被人类阅读的高级编程语言。它无法被计算机硬件直接认识执行。因此,C语言的源代码的执行需要经过几个步骤。C++其实算是C语言的超集,它是在C语言的基础上增加了额外特性的编程语言,因此过程也是类似的。理解C语言从源代码到最后的执行程序之间的转变过程可以帮助我们更好理解C语言编程。
一、可执行文件(executable file)的理解
在说明C语言的执行过程之前,我们需要理解一下可执行文件。可执行文件通常可以理解成能够直接被计算机硬件所执行的程序文件。它是一种二进制文件。现代的可执行文件大多数都借助操作系统运行(由于很多程序都使用了操作系统提供的接口来使用硬件资源,如内存、CPU等),因此可执行文件通常都是依赖操作系统的文件。当然,也有一些可执行文件可以直接被CPU从硬盘中读取加载执行,这里就不多赘述了。
在windows下的exe文件,Linux下的ELF( Executable and Linking Format)文件(扩展名是o的文件)都是可执行文件。它们都可以被操作系统直接读取执行。那么,这里所说的C语言的执行过程就是C语言是如何从源文件(文本代码)转变成最终的可执行文件的过程。
大体上,C语言的源代码需要经过如下步骤转成可执行的程序:
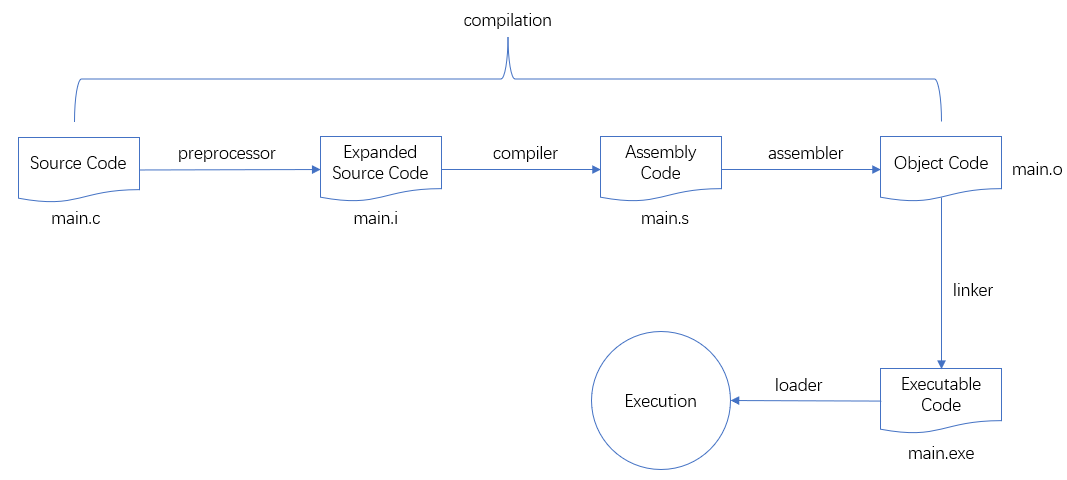
简而言之就是,C语言的源代码首先需要经过编译(compilation)过程变成对象代码(obj code),然后经过连接器(linker)的连接(linking)过程就能变成可执行文件了。编译作为第一个大阶段,其中还包含了预处理、编译、汇编三个步骤。 接下来我们详细描述这个过程。
可以看到,很多内容都被替换了。当然,这个文档很长,我只展示了前面几行。这个.i结尾的文件就是扩展的源代码文件。 汇编代码已经是接近机器语言的代码了,它的代码都对应着机器代码的指令。一般做嵌入式开发的同学们可能了解比较多。但这也是编译过程中一个结果文件。生成这样的文件其实有利于我们知道机器硬件是如何执行程序的,有助于我们优化代码。

