集成学习(Ensemble Learning)简介及总结
一、基本思想
**集成学习(Ensemble Learning)**是解决有监督机器学习任务的一类方法,它的思路是基于多个学习算法的集成来提升预测结果。
通常情况下,有监督的学习方法都是针对一个问题从一个有限的假设空间中搜索最适合结果。这里就包含了两个问题,一个是假设空间中是否包含了合适的方案,另一个是假设这个方案存在,模型是否可以搜寻到。而集成学习就是将多个假设空间放到一起来形成一个更好的方案。
集成学习的结果是一个单一的假设空间,不一定是在原始分类器的假设空间中,因此具有更高的灵活性。理论上说,集成学习可以在训练集上比单一的模型有更好的拟合能力,而某些集成学习方法(如bagging)在实际中也能更好地降低过拟合的问题。集成学习也会给予分类性能好的分类器更高的权重。
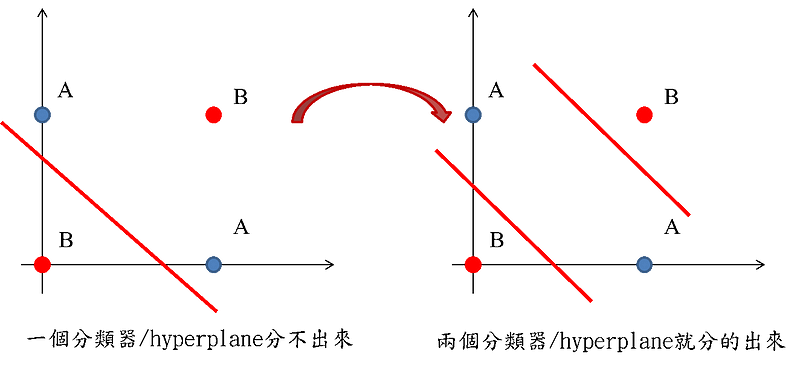
如上图所示,单个线性分类器可能无法分割上述数据,但是两个线性分类器就可以了。这是集成学习一个简单的举例。
二、集成学习的分类
集成学习的集成方式分成两种,一种是串行(squential ensemble),一种是并行(parallel ensemble)。
串行集成的意思是基分类器以串行的方式连接,它的动机是为了探索基分类器之间的依赖关系,通过对前一个错分的数据提高权重来提升性能。串行的集成学习方法的过程一般是对整个训练集使用一个基分类器训练,然后将基分类器表现不好的样本提升权重,再使用第二个基分类器进行训练在,直到训练到指定的第$T$个基分类器。
而并行集成的方法利用基分类器之间的独立性,通过基分类器之间的加权投票得到最终结果。因此,并行集成下的基分类器需要有较大的差异性,否则无法有效提升预测性能(因为大家都差不多,投票也没意义)。因此,并行集成方法首先将训练数据随机切分成$M$块,然后每一块训练集使用$T$个基分类器训练,最终加权投票得到最终结果。
集成学习有几种不同的类型: 贝叶斯优化 bagging boosting stacking
三、集成学习方法的参数数量影响
Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。
对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差,所以需要更多关注单个分类器的偏差问题,那么单个分类器需要较深的树或者不剪枝的树来提高其精度。而对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
