爬虫聚焦——以新浪微博为例
网络爬虫是实现网页数据获取的一般方法,并且需要先成功模拟微博登陆后,再进入设定好的入口URL 地址,将网页内容按某种策略以文本形式存于某存储系统中, 同时抓取网页中其他的可用来作为二级爬行入口的有效地址, 直到满足已定抓取条件或抓取结束后爬虫程序停止。但是,由于网页是通过HTML语言标记元素的,所以在获取网页信息时候需针对数据的不同标签分别进行抓取。这一获取方法实现的前提是需要先登陆微博,只有在登陆成功之后网页的相应cookie值才会被保存下来,但是,由于微博平台的相关设置,一般的网络爬虫获取数据的限制很大,所以如何取得微博网站的“信任”也是一大重要问题。同时,由于微博数据形式的多样化,包含文本、表情、超链接、地理位置、用户关系等,这也增加了获取数据的难度。除此之外,微博爬虫程序存在一个效率较低的问题,同时这种方式获取的数据往往是杂乱的,因此如何规范获取数据和提高爬取效率又是另一大问题。所以说,“爬虫”,懂了都简单,刚入门还是要好好花点心思的哦。
一、知彼
在研究微博数据的获取方法之前,需要先了解微博页面的信息架构,明确我们需要获取的数据在网页上的呈现形式,然后分析网页的源代码和网页数据流情况,确定微博界面解析和页面数据获取的必要技术手段,这样,才能更好的发现待解决的问题并提出解决方案。
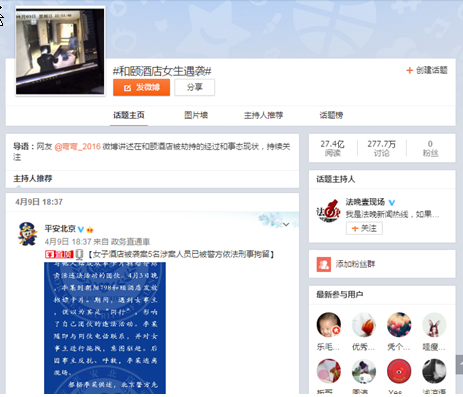
如果想要分析面向特定话题的微博页面(话题主页和评论页),其信息结构如下(这里博主随意选了“和颐酒店女生遇袭”话题页面来分析):